
#21 - 06/2021
- 01001100110121 – cyborg
- Το όνειρο του μετα-ανθρωπισμού είναι εφιάλτης!
- Πώς μπορεί να σωθεί η φιλελεύθερη δημοκρατία; Αυτοκτονώντας
- Ειρηνική χρήση των βιολογικών όπλων...
- Semantic technology: η αναδιάρθρωση του νοήματος
- Διαβατήρια ανοσοποίησης
- “Πράσινη ενέργεια”: καθόλου επί γης ειρήνη!!!
- Άρτος και θεάματα - εμβόλια και αθλήματα
- Reality shop (η πραγματικότητα σαν εμπόρευμα)
- bytes & genes
Semantic technology: η αναδιάρθρωση του νοήματος
Κάποιες φορές στο διαδίκτυο μας ζητάται να αποδείξουμε ότι δεν είμαστε ρομπότ. Συνήθως συμβαίνει σε περιπτώσεις δημιουργίας λογαριασμών στις διάφορες πλατφόρμες ή στην ταυτοποίησή μας κατα την είσοδο σε αυτές. Με αυτόν τον τρόπο οι πλατφόρμες αυτές προσπαθούν να αντιμετωπίσουν τυχόν «κακόβουλα» προγράμματα που έχουν φτιαχτεί με σκοπό να δημιουργούν αυτοματοποιημένα πολλούς λογαριασμούς ή να δοκιμάζουν επανειλλημένως διάφορους κωδικούς ώστε να αποκτήσουν πρόσβαση σε τρίτους λογαριασμούς.
Η λειτουργία αυτή ονομάζεται CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) και αναφέρεται συχνά και ως αντίστροφο Turing test. [1Το Turing test είναι μια διαδικασία με την οποία εξετάζεται το κατά πόσο ένας υπολογιστής μπορεί να προσομοιώσει την ανθρώπινη νοημοσύνη. Το τεστ γίνεται με την μορφή γραπτών ερωτο-απαντήσεων μεταξύ ενός ανθρώπου και δύο κρυμμένων «συνομιλιτών», ενός ανθρώπου και ενός υπολογιστή. Η αξιολόγηση γίνεται στην βάση της αναγνώρισης από τον πρώτο του ποιός είναι ο άνθρωπος και ποιός η μηχανή.] Εμφανίζεται ως μια εικόνα με στρεβλωμένα γράμματα και αριθμούς, όπου θα πρέπει να τα αναγνωρίσουμε και να τα πληκτρολογήσουμε ή ως μια φωτογραφία στην οποία θα πρέπει να τσεκάρουμε τα σημεία στα οποία φαίνεται ένα αντικείμενο το οποίο μας περιγράφεται σε μια πρόταση (πχ επιλέξτε τα σημεία της φωτογραφίας με τις διαβάσεις).
Ο λόγος που αυτό δουλεύει, είναι επειδή ο αλγόριθμος του «κακόβουλου» προγράμματος δεν έχει την ικανότητα να αναγνωρίσει την μορφή των γραμμάτων στην πρώτη περίπτωση ή να καταλάβει ποιό είναι το αντικείμενο που αναζητείται στη δεύτερη και στην συνέχεια να αναγνωρίσει την μορφή του μέσα στην φωτογραφία. Σίγουρα όχι με την ακρίβεια που μπορεί ένας άνθρωπος και πιθανότατα όχι για πολύ ακόμα. Έτσι καλείται ο άνθρωπος-χρήστης να επιβεβαιώσει ότι είναι άνθρωπος (και μόνο αυτό, όχι ότι είναι ο συγκεκριμένος άνθρωπος) επιδεικνύοντας μια ικανότητα που δεν έχει η μηχανή. Αυτή της ερμηνείας.
Αν και το πεδίο που καλείται για να καλύψει αυτό το κενό προς όφελος της μηχανής, είναι περισσότερο αυτό της αναγνώρισης εικόνων (visual recognition), υπάρχει ανάγκη και για την «κατανόηση» (από την μεριά της μηχανής) αυτού που ζητείται ως αντικείμενο. Της ερμηνείας δηλαδή της λέξης ή της πρότασης σε μια μορφή και έπειτα στην αναγνώριση αυτής της μορφής μέσα στην εικόνα. Έτσι το ζητούμενο δεν είναι απλά η ταυτοποίηση της εικόνας-δείγμα με κάποια από αυτές που μπορεί να έχει η μηχανή αποθηκευμένες σε μια βάση δεδομένων, ώστε να βρει την αντίστοιχη με βάση την σύγκριση· αλλά η ίδια η διαδικασία της απόδοσης και αντίληψης του νοήματος που έχουν οι λέξεις και τα πράγματα.

Η διαφορά με το πώς μπορεί να φαντάζεται κανείς ότι η μηχανή εξάγει συμπεράσματα, μαζεύοντας τόνους δεδομένων και μετα-δεδομένων τα οποία τα αποθηκεύει, τα κατηγοριοποιεί φτιάχνοντας στατιστικές και διαγράμματα (μια στατική διαδικασία αν το σκεφτούμε, όπου το κάθε επόμενο βήμα είναι απλά η αύξηση των δεδομενών και ο επανασχεδιασμός των στατιστικών), είναι πως στην περίπτωση της τεχνολογίας των semantics το ζητούμενο είναι ο ορισμός των μεταξύ τους σχέσεων, πάνω στις οποίες η μηχανή θα βασιστεί ώστε να προχωρήσει σε νέα συμπεράσματα που δεν προκύπτουν άμεσα από αυτά τα δεδομένα και τις δηλωμένες σχέσεις· να κατασκευάσει νέες σχέσεις που δεν της έχουν ορισθεί και να αποκτήσει έτσι την ικανότητα της ερμηνείας.
Ένα πράγμα που πρέπει να έχουμε κατά νου όταν προσπαθούμε να προσεγγίσουμε το ζήτημα των «έξυπνων» μηχανών, είναι ότι μιλάμε για ένα σύνολο τεχνολογιών που συνθέτουν το πεδίο της τεχνητής νοημοσύνης· ότι είναι δηλαδή μια «συνεργασία» πολλών πεδίων που είναι απαραίτητα, όπως: τα νευρωνικά δίκτυα, οι αλγόριθμοι μηχανικής μάθησης, η ρομποτική, η αναγνώριση εικόνων, η επεξεργασία φυσικής γλώσσας κ.α. Έτσι, το πεδίο των semantics είναι και αυτό ένα κομμάτι στο ψηφιδωτό της αναζήτησης μιας – όσο το δυνατό - «ανθρώπινης» μηχανής.
Αυτό που καλύπτει η τεχνολογία semantics σε αυτή την αναζήτηση είναι η αναπαράσταση της γνώσης και η δημιουργία συλλογισμών. Μεταφράζουμε από το σχετικό λήμμα στη wikipedia: [2https://en.wikipedia.org/wiki/Knowledge_representation_and_reasoning]
Η αναπαράσταση της γνώσης και η συλλογιστική είναι το πεδίο της τεχνητής νοημοσύνης που είναι αφιερωμένο στην αναπαράσταση πληροφοριών για τον κόσμο σε μια μορφή που ένα σύστημα υπολογιστών μπορεί να χρησιμοποιήσει για την επίλυση πολύπλοκων εργασιών όπως η διάγνωση μιας ιατρικής κατάστασης ή ο διάλογος σε μια φυσική γλώσσα. Η αναπαράσταση της γνώσης ενσωματώνει ευρήματα από την ψυχολογία σχετικά με το πώς οι άνθρωποι επιλύουν προβλήματα και αντιπροσωπεύουν τη γνώση προκειμένου να σχεδιάσουν φορμαλισμούς που θα κάνουν τα σύνθετα συστήματα ευκολότερα στο σχεδιασμό και την κατασκευή. Η αναπαράσταση της γνώσης και η συλλογιστική ενσωματώνουν επίσης ευρήματα από τη λογική για την αυτοματοποίηση διαφόρων ειδών συλλογισμού, όπως η εφαρμογή κανόνων ή οι σχέσεις των συνόλων και υποσυνόλων. Παραδείγματα φορμαλισμού αναπαράστασης γνώσης περιλαμβάνουν σημασιολογικά δίκτυα (semantic nets), αρχιτεκτονική συστημάτων, πλαίσια, κανόνες και οντολογίες.
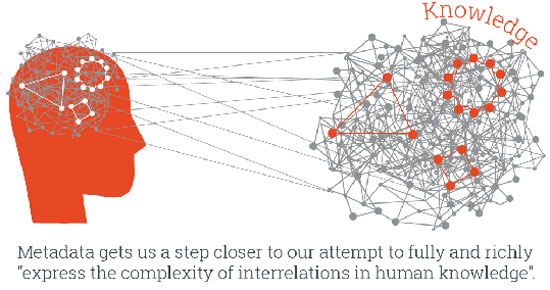
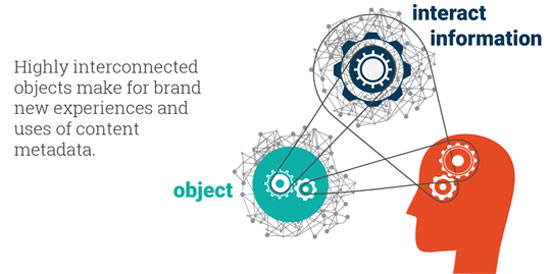
Ένα βήμα πιο κοντά στη διαλειτουργικότητα: Σημασιολογικά μετα-δεδομένα (semantic metadata) [3One step closer to intertwingularity: Semantic Metadata - https://www.ontotext.com/blog/semantic-metadata/]
Τα μετα-δεδομένα αλλάζουν ριζικά τον τρόπο που σκεφτόμαστε και χρησιμοποιούμε τις πληροφορίες για τη δημιουργία και τη μεταφορά γνώσεων. Τα σημασιολογικά μετα-δεδομένα ακόμη περισσότερο.
Μας επιτρέπουν να προσθέσουμε τόση λεπτομέρεια σε ένα υπάρχον αντικείμενο, να το συνδέσουμε σε έναν ατελείωτο αριθμό άλλων αντικειμένων και να διευκολύνουμε την αναζήτηση, την πρόσβαση και τη χρήση. Και ακόμα κι αν απέχουμε πολύ ακόμα από αυτό που ο Ted Nelson [4Η Διαλειτουργικότητα (Intertwingularity) είναι ένας όρος που επινοήθηκε από τον Ted Nelson για να εκφράσει την πολυπλοκότητα των αλληλεπιδράσεων στην ανθρώπινη γνώση. Ο Nelson έγραψε στο Computer Lib / Dream Machines (Nelson 1974): «Όλα είναι βαθειά διασυνδεδεμένα. Με μια έννοια δεν υπάρχουν καθόλου "υποκείμενα". Υπάρχει μόνο η γνώση, αφού οι διασυνδέσεις μεταξύ των μυριάδων θεμάτων αυτού του κόσμου απλά δεν μπορούν να διαχωριστούν ξεκάθαρα.»] αποκαλεί Διαλειτουργικότητα, η σωστή ρύθμιση των μετα-δεδομένων – δηλαδή που ρυθμίζονται σωστά με σημασιολογικές τεχνολογίες - μας φέρνει ένα βήμα πιο κοντά στην προσπάθειά μας να εκφράσουμε πλήρως και πλούσια «την πολυπλοκότητα των αλληλεπιδράσεων στην ανθρώπινη γνώση».
Με το «ήσυχο βούισμά τους» κάτω από κάθε ψηφιακή δραστηριότητα, τα μετα-δεδομένα διαδραματίζουν μετασχηματιστικό ρόλο στους τρόπους που αλληλεπιδρούμε με τις πληροφορίες.
Όπως αναφέρει ο καθηγητής Jeffrey Pomeranz, συγγραφέας του βιβλίου Metadata: «Τα μετα-δεδομένα, όπως το ηλεκτρικό δίκτυο και το σύστημα αυτοκινητόδρομων, εξασθενούν στο πλαίσιο της καθημερινής ζωής, θεωρούνται δεδομένα (στμ: με την έννοια της βεβαιότητας) ως μέρος αυτού που κάνει τη σύγχρονη ζωή να λειτουργεί ομαλά.
Εάν παρακολουθείτε τα προτεινόμενα βίντεο στο youtube ή χρησιμοποιείτε το τηλέφωνό σας για να βρείτε τα πλησιέστερα εστιατόρια ή κάνετε μια αναζήτηση στο amazon, αποκομίζετε ήδη τα οφέλη των «δεδομένων για τα δεδομένα» (όπως ορίζονται συχνά τα μετα-δεδομένα). Άλλα παραδείγματα μετα-δεδομένων εκτείνονται από το μέγεθος και τη μορφή των ψηφιακών βιβλίων και των εγγράφων μας, μέχρι τις ημερομηνίες δημιουργίας των αρχείων μας, μέχρι τα δεδομένα αισθητήρων από τις έξυπνες συσκευές μας και το τελευταίο τραγούδι που αναζητήσαμε στο itunes.
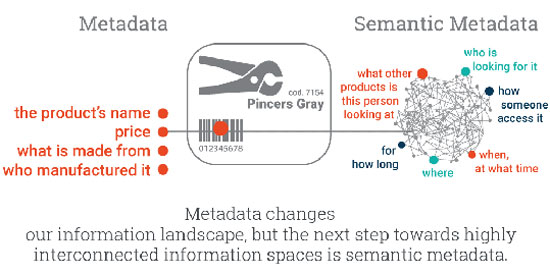
Όσο θεμελιωδώς τα μετα-δεδομένα και να αλλάζουν το τοπίο των πληροφοριών, είναι μόνο η αρχή. Το επόμενο βήμα προς ένα διασυνδεδεμένο χώρο πληροφοριών είναι τα σημασιολογικά μετα-δεδομένα. Αυτό που διαφοροποιεί τα σημασιολογικά μετα-δεδομένα από τα μετα-δεδομένα είναι το επίπεδο διασύνδεσης. Τα σημασιολογικά μετα-δεδομένα είναι βαθιά αλληλένδετα και πλούσια σε συμφραζόμενα. Σκεφτείτε μια ετικέτα τιμής σε ένα κατάστημα. Εννοιολογικά, αυτή η ετικέτα είναι ένα πολύ βασικό παράδειγμα μετα-δεδομένων.
Περιέχει πληροφορίες που προορίζονται για τον πελάτη, όπως το όνομα του προϊόντος, την τιμή του, ποιος το έφτιαξε κλπ. Ωστόσο, η ετικέτα περιέχει επίσης έναν γραμμικό κώδικα (barcode) και πολλούς άλλους κωδικούς που συνήθως είναι αναγνώσιμοι μόνο από την μηχανή και χρησιμοποιούνται για την αυτοματοποίηση της διαδικασίας της αγοράς στο κατάστημα.
Έχει όμως κάποιο νόημα για εμάς αυτό το τελευταίο μετα-δεδομένο, αυτό στο γραμμωτό κώδικα; Μπορούμε να κατανοήσουμε τα σύμβολα και τα σημάδια σε αυτό και να τα συσχετίσουμε με άλλα συνδεδεμένα γεγονότα;
Όχι, δεν μπορούμε. Χωρίς να δοθεί πρόσθετο νόημα στους κωδικούς, τα στοιχεία πληροφοριών θα έχουν περιορισμένη αξία, επειδή δεν θα μπορούμε να τα συσχετίσουμε με οτιδήποτε άλλο. Έτσι, για να τα ερμηνεύσουμε, πρέπει να χρησιμοποιήσουμε σημασιολογικά μετα-δεδομένα.
Ομολογουμένως, η διαφοροποίηση μεταξύ μετα-δεδομένων και σημασιολογικών μετα-δεδομένων είναι δύσκολη. Αλλά εκεί όπου τα σημασιολογικά μετα-δεδομένα αναδεικνύονται είναι μέσω των σημασιολογικών τεχνολογιών, με τη βοήθεια των οποίων αυτά τα δεδομένα (ή μετα-δεδομένα) διαμορφώνονται για να εκφράζουν νόημα.
Φανταστείτε ότι τα στοιχεία αυτής της ίδιας ετικέτας συνδέονται με ένα ευρύ φάσμα πρόσθετων διασυνδεδεμένων πληροφοριών: τον ιστότοπο του κατασκευαστή, ποιοι είναι, ποια άλλα προϊόντα προσφέρουν, σε ποια κατηγορία ανήκει το προϊόν, άλλα προϊόντα παρόμοια, κλπ. Φανταστείτε τώρα μια άλλη ομάδα μετα-δεδομένων που περιέχει πληροφορίες με βάση τα συμφραζόμενα όπως: ποιος την κοιτάζει, ποιά ώρα, πού, για πόση ώρα, ποια άλλα προϊόντα κοιτούσε αυτό το άτομο και ούτω καθεξής.
Αυτό που προκύπτει είναι μια εξαιρετικά προσαρμόσιμη, εξαιρετικά εξατομικεύσιμη δυναμική πληροφοριοποίηση που έχει τη δυνατότητα αλλαγής, ανάλογα με το ποιος, πότε, πού και πώς κάποιος έχει πρόσβαση σε αυτήν. Και όσο κι αν μπορεί να ακούγεται το sci-fi, δεν είναι. Είναι αυτό ακριβώς που κατασκευάζει τα σημασιολογικά μετα-δεδομένα.
Με τα σημασιολογικά μετα-δεδομένα, οι λεπτομέρειες της τιμής θα συνδέονται με τους αναγνώσιμους-από-την-μηχανή ορισμούς τους, μεταξύ τους αλλά και με εξωτερικές πηγές. Έτσι, τα μετα-δεδομένα από την ετικέτα, μαζί με όλα τα στοιχεία της, θα αποκτήσουν πολύτιμο νόημα και η ετικέτα θα μετατραπεί σε ένα αντικείμενο υψηλής διασύνδεσης.
Με τη σύνδεση εκατοντάδων εκατομμυρίων οντοτήτων, μεγάλες εταιρείες μέσων ενημέρωσης, επιχειρήσεις και μη κερδοσκοπικοί οργανισμοί δημιουργούν ήδη μαγευτικές και διορατικές εμπειρίες από τα σημασιολογικά μετα-δεδομένα. Όπως επισημαίνει και o Yosi Glic στo άρθρο του “Η κατανόηση της πραγματικής αξίας της σημασιολογικής ανακάλυψης”, όταν γράφει για το Netflix και τις ετήσιες επενδύσεις τους ύψους 150 εκ. δολαρίων σε σημασιολογικές τεχνολογίες:
«Μόνο η σημασιολογική τεχνολογία μπορεί να ξέρει αν ένας χρήστης προτιμά για ψυχαγωγία έναν “σκληρό στρατό ενός ατόμου”, έναν “αγώνα ενάντια στο χρόνο”, “τους εγκληματικούς ήρωες” ή “μια ρομαντική ταινία”.”
Είναι αλήθεια. Με τα σημασιολογικά μετα-δεδομένα, οι ευκαιρίες διασύνδεσης είναι ατελείωτες. Εμπλουτίζοντας την ταυτότητα, την εύρεση και τη χρησιμότητα των ψηφιακών πόρων, τα σημασιολογικά μετα-δεδομένα επιτρέπουν στον χρήστη να γνωρίζει περισσότερα.
Η κατανόηση των σημασιολογικών μετα-δεδομένων και η αξιοποίησή τους για τη δημιουργία και την κατανάλωση περισσότερων διασυνδεδεμένων, πλουσιότερων, καλά δομημένων και ανακτήσιμων πόρων μπορεί να έχει άμεσο αντίκτυπο στα κέρδη και την απόδοση ενός οργανισμού. Διότι, όταν όλα συνδέονται, τα στοιχεία συνδυάζονται πιο εύκολα, ενώνονται, επανατοποθετούνται και τελικά γίνονται κατανοητά.
Δομή και συστατικά των σημασιολογικών μετα-δεδομένων
Τα semantics λοιπόν ψάχνουν το νόημα μέσα από τις σχέσεις, για να το μεταφράσουν σε μια γλώσσα που θα καταλαβαίνει η μηχανή, ώστε να φτάσει στο σημείο να μπορεί από μόνη της να βγάζει συμπεράσματα. Να είναι σε θέση δηλαδή να ερμηνεύει τις γραμμές κώδικα που «διαβάζει» (: έχει ως είσοδο), με βάση την διασυνδεσιμότητά τους με άλλες γραμμές κώδικα (: ψηφιακή αναπαράσταση των σχέσεων) και να εξάγει νέες γραμμές κώδικα (: ψηφιακές αναπαραστάσεις νέων σχέσεων), που προκύπτουν από τα προηγούμενα, κοκ.
Όλα αυτά στην βάση μιας προσομοίωσης της όποιας πολυπλοκότητας μπορεί να «εξορυχθεί» από τα αντικείμενα και τις μεταξύ τους σχέσεις, αφού αυτός ο υπολογισμός είναι περιορισμένος στις δυνατότητες των μηχανών που στον πυρήνα της «σκέψης» τους όλα απλοποιούνται σε 0 και 1. Μέχρι, βέβαια να μπουν σε ευρύτερη λειτουργία οι κβαντικοί υπολογιστές, αλλά αυτό είναι ένα άλλο θέμα.
Με αυτή την απλοποίηση που κάνουν οι μηχανές στο εσωτερικό τους κατα νου, θα κάνουμε μια γενική αναφορά στον τρόπο που υλοποιούνται τα semantics στην πράξη· στον τρόπο που προσπαθούν να οργανώσουν τα δεδομένα και να σχηματίσουν τις μεταξύ τους σχέσεις.
Τα πρότυπα για τα semantics έχουν σχεδιαστεί και ορισθεί από την «Κοινοπραξία του Παγκόσμιου Ιστού» (WWW Consortium ή W3C), την κύρια οργάνωση διεθνών προτύπων για το διαδίκτυο. Ο ίδιος οργανισμός είναι που έχει διαμορφώσει δηλαδή και τα πρότυπα με βάση τα οποία λειτουργεί το Ιnternet (HTTP, HTML κλπ). Τα βασικά «συστατικά» των semantics είναι τα εξής:
Το RDF Schema, ένα σύνολο κατηγοριών με ορισμένες ιδιότητες που χρησιμοποιούν το μοντέλο δεδομένων εκπροσώπησης γνώσης RDF, παρέχοντας βασικά στοιχεία για την περιγραφή οντολογιών. Μπορούν να αποθηκευτούν σε «τρίγωνα» (triplestones): ειδικά σχεδιασμένες βάσεις δεδομένων για την αποθήκευση και την ανάκτηση «τριπλών» μέσω σημασιολογικών ερωτηματών (semantic queries). Ένα «τριπλό» αποτελείται από αντικείμενο-δήλωση-αντικείμενο. Για παράδειγμα “Ο Γιάννης είναι 40” ή “Ο Γιάννης γνωρίζει τον Γιώργο”.
Τα σημασιολογικά ερωτήματα στην συνέχεια, για την ανάκτηση πληροφοριών από τα RDF, γίνονται με την γλώσσα SPARQL, η οποία είναι σαν όλες τις γλώσσες ανάκτησης πληροφοριών από βάσεις δεδομένων (πχ SQL), εξειδικευμένη όμως στην ανάκτηση semantic μετα-δεδομένων.
Με τις δύο παραπάνω τεχνολογίες γίνεται η αποθήκευση και η αναζήτηση των μετα-δεδομένων με «όρους semantics»· με τρόπο δηλαδή που να περιλάμβανονται και οι μεταξύ τους σχέσεις. Και με βάση αυτά είναι εφικτή η δημιουργία «οντολογιών», μιας αναπάραστασης δηλαδή των ονομάτων, των ορισμών, των ιδιοτήτων, των εννοιών και των οντοτήτων, που υπάρχουν σε έναν η περισσότερους τομείς, καθώς και των μεταξύ τους σχέσεων. Πιο απλά, μια οντολογία είναι ένας τρόπος για να δείξουμε τις ιδιότητες μιας θεματικής περιοχής και το πώς σχετίζονται, καθορίζοντας ένα σύνολο εννοιών και κατηγοριών που αντιπροσωπεύουν το θέμα.
Τον ορισμό της «οντολογίας», όσον αφορά την επιστήμη των υπολογιστών, τον έχει δώσει ο αμερικάνος Thomas Gruber [5O Thomas Gruber είναι επίσης και ο συν-ιδρυτής της εταιρείας Siri Inc, που κατασκεύασε την ψηφιακή προσωπική βοηθό Siri, η οποία αγοράστηκε από την Apple to 2010 και υπάρχει πλέον σε κάθε συσκευή της. Στο πλούσιο βιογραφικό του μπορεί να βρει κανείς την συνεισφορά του στο τομέα της τεχνητής νοημοσύνης και της διεπαφής με τον χρήστη, την συνεργασία του με πολλές εταιρείες καθώς και με την DARPA. Τα τελευταία χρόνια προωθεί την ιδέα του περί «ανθρωπιστικής τεχνητής νοημοσύνης» (Humanistic AI). Για περισσότερα δείτε και την σχετική ομιλία του στο TED.] πρώτη φορά το 1992, για να τον ενημερώσει το 2009. Μεταφράζουμε το σχετικό κείμενο, αφού η έννοια της «οντολογίας» βρίσκεται στον πυρήνα της λειτουργίας των semantics.
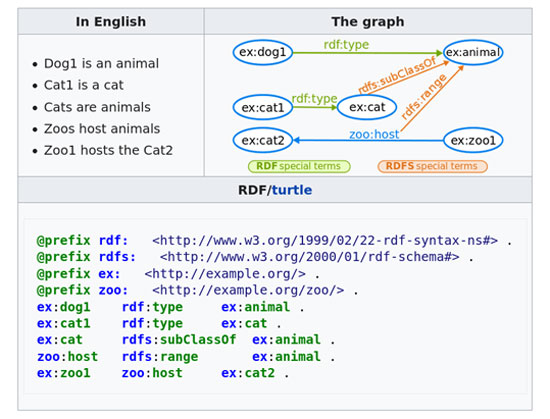
Παράδειγμα ενός RDF Schema
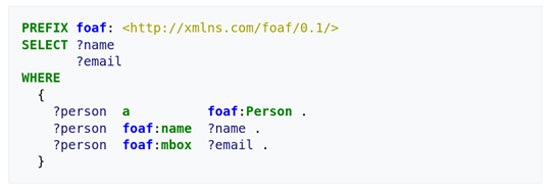
Παράδειγμα ερώτησης σε κάποιο RDF, μέσω της γλώσσας SPARQL. Το συγκεκριμένο θα επιστρέψει τα ονόματα και τα emails όλων των προσώπων στην βάση.
Οντολογία [6Ontology, by Tom Gruber, in the Encyclopedia of Database Systems, Ling Liu and M. Tamer Özsu (Eds.), Springer-Verlag, 2009.]
Ορισμός
Στο πλαίσιο των επιστημών των υπολογιστών και των πληροφοριών, μια οντολογία καθορίζει ένα σύνολο πρωταρχικών αναπαραστάσεων με τις οποίες μπορεί να μοντελοποιηθεί ένας τομέας γνώσης ή λόγου. Τα αντιπροσωπευτικά πρωταρχικά είναι συνήθως τάξεις (ή σύνολα), χαρακτηριστικά (ή ιδιότητες) και σχέσεις (ή σχέσεις μεταξύ των μελών της τάξης). Οι ορισμοί των αντιπροσωπευτικών πρωταρχικών περιλαμβάνουν πληροφορίες σχετικά με τη σημασία τους και τους περιορισμούς στη λογικά συνεπή εφαρμογή τους. Στο πλαίσιο των συστημάτων των βάσεων δεδομένων, η οντολογία μπορεί να θεωρηθεί ως ένα επίπεδο αφαίρεσης των μοντέλων δεδομένων, αντίστοιχο με τα ιεραρχικά και σχεσιακά μοντέλα, αλλά που προορίζεται για την μοντελοποίηση γνώσεων όσον αφορά τα άτομα, τα χαρακτηριστικά τους και τις σχέσεις τους με άλλα άτομα. Οι οντολογίες περιγράφονται συνήθως σε γλώσσες που επιτρέπουν την αφαίρεση από δομές δεδομένων και στρατηγικές εφαρμογής. Στην πράξη οι γλώσσες οντολογιών είναι πιο κοντά στην εκφραστική ισχύ της λογικής πρώτου βαθμού, από τις γλώσσες που χρησιμοποιούνται για τη μοντελοποίηση των βάσεων δεδομένων. Για το λόγο αυτό, οι οντολογίες λέγονται ότι βρίσκονται στο «σημασιολογικό» επίπεδο, ενώ τα σχήματα βάσεων δεδομένων είναι μοντέλα δεδομένων στο «λογικό» ή «φυσικό» επίπεδο. Λόγω της ανεξαρτησίας τους από τα μοντέλα δεδομένων χαμηλότερου επιπέδου, οι οντολογίες χρησιμοποιούνται για την ενσωμάτωση ετερογενών βάσεων δεδομένων, επιτρέποντας τη διαλειτουργικότητα μεταξύ διαφορετικών συστημάτων και τον καθορισμό διεπαφών σε ανεξάρτητες γνωσιακές υπηρεσίες. Στη ταξινόμηση της τεχνολογίας των προτύπων του Σημασιολογικού Ιστού (Semantic Web), οι οντολογίες αναφέρονται ως ένα ξεχωριστό επίπεδο. Και πλέον υπάρχουν γλώσσες και μια ποικιλία από εμπορικά και ανοιχτού κώδικα εργαλεία για τη δημιουργία και την επεξεργασία οντολογιών.
Ιστορικό υπόβαθρο
Ο όρος «οντολογία» προέρχεται από το πεδίο της φιλοσοφίας που ασχολείται με τη μελέτη του «Είναι» ή της ύπαρξης. Στη φιλοσοφία, μπορεί κανείς να μιλήσει για μια οντολογία ως μια θεωρία της φύσης της ύπαρξης (π.χ., η οντολογία του Αριστοτέλη προσφέρει πρωτόγονες κατηγορίες, όπως ουσία και ποιότητα, οι οποίες υποτίθεται ότι ευθύνονται για όλα όσα «Είναι»). Στην επιστήμη των υπολογιστών και της πληροφορίας, η οντολογία είναι ένας τεχνικός όρος που υποδηλώνει ένα τεχνούργημα που έχει σχεδιαστεί για έναν σκοπό: να επιτρέψει τη μοντελοποίηση γνώσεων για κάποιο τομέα, πραγματικό ή φανταστικό.
Ο όρος είχε υιοθετηθεί από πρώιμους ερευνητές τεχνητής νοημοσύνης, οι οποίοι αναγνώρισαν τη δυνατότητα εφαρμογής της μαθηματικής λογικής και υποστήριξαν ότι θα μπορούσαν να δημιουργήσουν νέες οντολογίες ως υπολογιστικά μοντέλα που να επιτρέπουν ορισμένα είδη αυτοματοποιημένης συλλογιστικής. Τη δεκαετία του 1980, η κοινότητα της τεχνητής νοημοσύνης χρησιμοποίησε τον όρο οντολογία για να αναφερθεί τόσο σε μια θεωρία ενός διαμορφωμένου κόσμου (π.χ., της απλοποιημένης φυσικής [7Naïve physics: η λαϊκή/απλοποιημένη φυσική είναι η ανεκπαίδευτη ανθρώπινη αντίληψη για τα βασικά φυσικά φαινόμενα. Στον τομέα της τεχνητής νοημοσύνης, η μελέτη της απλοποιημένης φυσικής αποτελεί μέρος της προσπάθειας τυποποίησης της κοινής γνώσης των ανθρώπων.]) όσο και σε ένα στοιχείο των γνωσιακών συστημάτων. [8Knowledge-based system: ένα πρόγραμμα υπολογιστή που αιτιολογεί και χρησιμοποιεί μια βάση γνώσεων για την επίλυση σύνθετων προβλημάτων.] Μερικοί ερευνητές, αντλώντας έμπνευση από τις φιλοσοφικές οντολογίες, θεώρησαν την υπολογιστική οντολογία ως ένα είδος εφαρμοσμένης φιλοσοφίας.
Στις αρχές της δεκαετίας του 1990, μια προσπάθεια δημιουργίας προτύπων διαλειτουργικότητας προσδιόρισε μια τεχνολογική ταξινόμηση που χαρακτήρισε το οντολογικό επίπεδο ως πρότυπο συστατικό των συστημάτων γνώσης (knowledge-based systems). Μια ευρέως αναφερόμενη ιστοσελίδα και ένα έγγραφο [9Toward principles for the design of ontologies used for knowledge sharing (https://tomgruber.org/writing/onto-design.htm)] που σχετίζονται με αυτήν την προσπάθεια πιστώνεται με έναν προσεκτικό ορισμό της οντολογίας ως τεχνικό όρο στην επιστήμη των υπολογιστών. Το έγγραφο ορίζει την οντολογία ως μια «σαφή προδιαγραφή της σύλληψης μιας έννοιας», η οποία με τη σειρά της αποτελείται από «τα αντικείμενα, τις έννοιες και τις άλλες οντότητες που υποτίθεται ότι υπάρχουν στην περιοχή ενδιαφέροντος και τις σχέσεις που διατηρούν μεταξύ τους». Ενώ οι όροι «προδιαγραφή» (specification) και «σύλληψη μιας ιδέας» (conceptualization) έχουν προκαλέσει πολλή συζήτηση, τα βασικά σημεία αυτού του ορισμού της οντολογίας είναι
- Μια οντολογία καθορίζει (προδιαγράφει) τις έννοιες, τις σχέσεις και τις άλλες διακρίσεις που σχετίζονται με τη μοντελοποίηση ενός τομέα.
- Η προδιαγραφή λαμβάνει τη μορφή των ορισμών του αντιπροσωπευτικού λεξιλογίου (τάξεις, σχέσεις και ούτω καθεξής), οι οποίοι παρέχουν έννοιες για το λεξιλόγιο και τους επίσημους περιορισμούς στη συνεκτική χρήση του.
Μια ένσταση σε αυτόν τον ορισμό είναι ότι είναι υπερβολικά ευρύς, επιτρέποντας μια σειρά προδιαγραφών από απλά γλωσσάρια έως ολόκληρες λογικές θεωρίες. Αυτό ισχύει όμως και για τα μοντέλα δεδομένων οποιασδήποτε πολυπλοκότητας. Για παράδειγμα, μια σχεσιακή βάση δεδομένων ενός μεμονωμένου πίνακα με μια μόνο στήλη, παραμένει μια οντότητα του σχεσιακού μοντέλου δεδομένων. Λαμβάνοντας μια πιο ρεαλιστική άποψη, μπορεί κανείς να πει ότι η οντολογία είναι ένα εργαλείο και προϊόν της μηχανικής και ως εκ τούτου ορίζεται από τη χρήση της. Από αυτή την οπτική γωνία, αυτό που έχει σημασία είναι η χρήση οντολογιών να παρέχει τους μηχανισμούς παρουσίασης με τους οποίους μπορούν να δημιουργηθούν μοντέλα σε βάσεις γνώσεων, να υποβάλλει ερωτήματα σε υπηρεσίες που βασίζονται στη γνώση και να εμφανίζει τα αποτελέσματα τέτοιων υπηρεσιών. Για παράδειγμα, η διασύνδεση σημασιολογικών εργαλείων σε μια υπηρεσία αναζήτησης μπορεί να προσφέρει απλά και μόνο ένα γλωσσάρι όρων με τους οποίους να διατυπώνονται ερωτήματα αναζήτησης, και αυτό θα λειτουργήσει ως οντολογία. Από την άλλη πλευρά, το σημερινό πρότυπο Σημασιολογικού Ιστού (Semantic Web) του W3C προτείνει έναν ειδικό φορμαλισμό για την κωδικοποίηση οντολογιών (OWL) [10Web Ontology Language (OWL): Η Γλώσσα Οντολογίας Ιστού είναι μια οικογένεια γλωσσών αναπαράστασης γνώσης για την συγγραφή οντολογιών στον Σημασιολογικό Ιστό (Semantic Web).], σε διάφορες παραλλαγές που ποικίλλουν σε εκφραστική ισχύ. Αυτό αντικατοπτρίζει την πρόθεση ότι μια οντολογία είναι μια προδιαγραφή ενός αφηρημένου μοντέλου δεδομένων που είναι ανεξάρτητο από τη συγκεκριμένη μορφή του.
Επιστημονικές βασικές αρχές
Η οντολογία συζητείται εδώ στο εφαρμοσμένο πλαίσιο του λογισμικού και της μηχανικής βάσεων δεδομένων, αλλά έχει και μια θεωρητική βάση. Μια οντολογία καθορίζει ένα λεξιλόγιο με το οποίο μπορούν να γίνουν ισχυρισμοί, οι οποίοι μπορεί να είναι είσοδοι σε ή έξοδοι από «πράκτορες γνώσης» (knowledge agents: π.χ. ένα πρόγραμμα λογισμικού). Ως προδιαγραφή της διεπαφής, η οντολογία παρέχει μια γλώσσα επικοινωνίας με τον πράκτορα. Ένας πράκτορας που υποστηρίζει αυτή τη διεπαφή δεν απαιτείται να χρησιμοποιεί τους όρους της οντολογίας ως εσωτερική κωδικοποίηση των γνώσεών του. Ωστόσο, οι ορισμοί και οι επίσημοι περιορισμοί της οντολογίας θέτουν περιορισμούς σε ό,τι μπορεί να δηλωθεί «με νόημα» σε αυτήν τη γλώσσα. Στην ουσία, η δέσμευση σε μια οντολογία (π.χ. η υποστήριξη μιας διεπαφής χρησιμοποιώντας το λεξιλόγιο της οντολογίας) απαιτεί οι δηλώσεις που γίνονται στις εισόδους και τις εξόδους να είναι λογικά συνεπείς με τους ορισμούς και τους περιορισμούς της οντολογίας. Αυτό είναι το ανάλογο με την απαίτηση ότι οι σειρές ενός πίνακα βάσης δεδομένων (ή οι δηλώσεις εισαγωγής πληροφοριών σε SQL) πρέπει να είναι συνεπείς με τους περιορισμούς ακεραιότητας, οι οποίοι δηλώνονται σαφώς και ανεξάρτητα από τις εσωτερικές μορφές δεδομένων (στμ: αναφέρεται στις κλασικές μη-σημασιολογικές βάσεις δεδομένων).
Ομοίως, παρότι μια οντολογία πρέπει να διατυπωθεί σε κάποια γλώσσα αναπαράστασης, προορίζεται να έχει μια προδιαγραφή σημασιολογικού επιπέδου - δηλαδή, να είναι ανεξάρτητη από τη στρατηγική ή την εφαρμογή της μοντελοποίησης των δεδομένων. Για παράδειγμα, ένα συμβατικό μοντέλο βάσης δεδομένων μπορεί να αντιπροσωπεύει την ταυτότητα των ατόμων χρησιμοποιώντας ένα κύριο κλειδί που αποδίδει ένα μοναδικό αναγνωριστικό σε κάθε άτομο. Ωστόσο, το πρωτεύον αναγνωριστικό κλειδί είναι ένα τεχνούργημα της διαδικασίας της μοντελοποίησης και δεν υποδηλώνει κάτι στον τομέα. Οι οντολογίες διατυπώνονται σε γλώσσες που είναι πιο κοντά στην εκφραστική ισχύ των λογικών φορμαλισμών, όπως η κατηγορηματική λογική.
Αυτό επιτρέπει στον σχεδιαστή οντολογίας να μπορεί να δηλώνει σημασιολογικούς περιορισμούς χωρίς να υποχρεώνεται σε μια συγκεκριμένη στρατηγική κωδικοποίησης. Για παράδειγμα, σε τυπικούς φορμαλισμούς οντολογίας κάποιος θα μπορούσε να πει ότι ένα άτομο είναι μέλος μιας τάξης ή έχει κάποια χαρακτηριστική τιμή χωρίς να αναφέρεται σε μοτίβα εφαρμογής όπως η χρήση αναγνωριστικών κλειδιών. Ομοίως, σε μια οντολογία κάποιος μπορεί να αντιπροσωπεύσει τους περιορισμούς που συγκρατούν τις σχέσεις με μια απλή δήλωση (π.χ. το Α είναι μια υποκατηγορία του Β), που θα μπορεί να κωδικοποιηθεί ως μια ένωση διαφορετικών κλειδιών στο σχεσιακό μοντέλο.
Η μηχανική της οντολογίας ασχολείται με τη λήψη αντιπροσωπευτικών επιλογών που αποτυπώνουν τις σχετικές διακρίσεις ενός τομέα στο υψηλότερο επίπεδο αφαίρεσης, ενώ εξακολουθεί να είναι όσο το δυνατόν πιο σαφής σχετικά με τις έννοιες των όρων. Όπως και σε άλλες μορφές μοντελοποίησης δεδομένων, απαιτείται γνώση και δεξιότητα. Η κληρονομιά της υπολογιστικής οντολογίας στη φιλοσοφική οντολογία είναι ένα πλούσιο σώμα θεωρίας για το πώς να κάνουμε οντολογικές διακρίσεις με συστηματικό και συνεκτικό τρόπο. Για παράδειγμα, πολλές από τις αντιλήψεις της «τυπικής οντολογίας» που βασίζονται στην κατανόηση του «πραγματικού κόσμου» μπορούν να εφαρμοστούν κατά τη δημιουργία υπολογιστικών οντολογιών για κόσμους δεδομένων. Όταν οι οντολογίες κωδικοποιούνται σε τυπικούς φορμαλισμούς, είναι επίσης δυνατό να επαναχρησιμοποιηθούν μεγάλες, προ-σχεδιασμένες οντολογίες της ανθρώπινης γνώσης ή γλώσσας. Σε αυτό το πλαίσιο, οι οντολογίες ενσωματώνουν τα αποτελέσματα της ακαδημαϊκής έρευνας και προσφέρουν μια λειτουργική μέθοδο για την μετατροπή της θεωρίας σε πράξη στα συστήματα βάσεων δεδομένων.
Semantic Web: το σημασιολογικό διαδίκτυο
Ενώ η τεχνολογία των σημασιολογικών μετα-δεδομένων μπορεί να σταθεί και σε έναν υπολογιστή, σε μια βάση δεδομένων ή σε ένα datacenter, να είναι μέρος ενός κλειστού δικτύου (π.χ. κάποιου πανεπιστημίου) ή κάποιου ερευνητικού κέντρου, οι πραγματικές της δυνατότητες ξεδιπλώνονται όταν αφεθεί «ελεύθερη» στον ωκεανό του κυβερνοχώρου. Εκεί ουσιαστικά εκπληρώνει το όνειρο [11Το οποίο προϋποθέτει και τις κρίσιμες υποδομές για μια ολοκληρωμένη dato-ποίηση: έξυπνες συσκευές παντού, internet των πραγμάτων (Internet of Things – IoT) και ικανό δίκτυο για να «σηκώσει» τον όγκο (5G, 6G κοκ).] κάθε «κυβερνο-προοδευτικού» για μια διαλειτουργικότητα των πάντων· όπως του δημιουργού του παγκόσμιου ιστού (WWW) Tim Berners-Lee. Ακολουθεί σχετική συνέντευξή του στο BusinessWeek, δημοσιευμένη από το Bloomberg: [12Q&A with Tim Berners-Lee - The inventor of the Web explains how the new Semantic Web could have profound effects on the growth of knowledge and innovation [Bloomberg - April 9 2007]]
Ο Tim Berners-Lee δεν έχει ξεμπερδέψει καθόλου με το World Wide Web. Έχοντας εφεύρει τον Ιστό το 1989, δουλεύει τώρα πάνω σε τρόπους για να το κάνει πολύ πιο έξυπνο. Την τελευταία δεκαετία, ως διευθυντής του World Wide Web Consortium (W3C), ο Berners-Lee εργάζεται σε μια προσπάθεια που ονομάστηκε «Σημασιολογικός Ιστός». Στην καρδιά του Σημασιολογικού Ιστού βρίσκεται η τεχνολογία που διευκολύνει τους ανθρώπους να βρίσκουν και να συσχετίζουν τις πληροφορίες που χρειάζονται, είτε αυτά τα δεδομένα βρίσκονται σε μια τοποθεσία Web, σε μια εταιρική βάση δεδομένων ή σε κάποιο λογισμικό.
Ο Σημασιολογικός Ιστός, όπως το βλέπει ο Berners-Lee, αντιπροσωπεύει μια τόσο βαθιά αλλαγή που δεν είναι πάντα εύκολο για τους άλλους να κατανοήσουν. Δεν είναι η πρώτη φορά που αντιμετωπίζει αυτό το πρόβλημα. «Ήταν πολύ δύσκολο να εξηγήσουμε τον Ιστό πριν οι άνθρωποι το συνηθίσουν, γιατί δεν είχαν καν λέξεις όπως κλικ και μετάβαση και ιστοσελίδα», λέει ο Berners-Lee. Σε μια πρόσφατη συνομιλία του με τον συγγραφέα του BusinessWeek.com Rachael King, ο Berners-Lee συζήτησε το όραμά του για το Σημασιολογικό Ιστό και πώς μπορεί να αλλάξει τον τρόπο λειτουργίας των εταιρειών.
Φαίνεται ότι ένα από τα προβλήματα που μπορεί να λύσει ο Σημασιολογικός Ιστός είναι το ξεκλείδωμα των πληροφοριών σε διάφορα σιλό, [13Στμ: Τα σιλό είναι κατασκευές που χρησιμοποιούνται για την τροφοδοσία (φόρτωση, εκφόρτωση) και την αποθήκευση χύδην στερεών υλικών. Ο όρος σιλό προέρχεται από το γαλλικό silo, το οποίο με τη σειρά του από το ισπανικό silo, «υπόγεια αποθήκη», με πιθανή προέλευση από το λατινικό sirus, το οποίο προέρχεται από το αρχαίο ελληνικό σιρός, «δοχείο ή λάκκος για φύλαξη σιτηρών». Στο παρόν χρησιμοποιείται μεταφορικά για ψηφιακούς χώρους αποθήκευσης.] σε διαφορετικές εφαρμογές λογισμικού και σε διαφορετικά μέρη που προς το παρόν δεν μπορούν να συνδεθούν εύκολα.
Ακριβώς. Όταν χρησιμοποιείτε τη λέξη «σιλό», αυτή είναι η λέξη που ακούμε όταν κάποιος στην επιχείρηση μιλάει για το πρόβλημα της ασυμβατότητας. Διαφορετικές λέξεις για το ίδιο πρόβλημα: οι επιχειρηματικές πληροφορίες εντός της εταιρείας διαχειρίζονται από διαφορετικά είδη λογισμικού και κάθε φορά πρέπει να απευθυνόμαστε σε ένα διαφορετικό άτομο και να μάθουμε ένα διαφορετικό πρόγραμμα για να τις χρησιμοποιήσουμε. Οποιοσδήποτε διευθύνων σύμβουλος επιχείρησης θα έπρεπε πραγματικά να είναι σε θέση να θέσει μια ερώτηση που να περιλαμβάνει τη διασύνδεση των δεδομένων ολόκληρου του οργανισμού, να είναι σε θέση να διευθύνει μια εταιρεία αποτελεσματικά και ειδικά να μπορεί να ανταποκρίνεται σε απρόσμενα γεγονότα. Οι περισσότεροι οργανισμοί δεν διαθέτουν αυτήν τη δυνατότητα να συνδέουν όλα τα δεδομένα μαζί.
Ακόμα και εξωτερικά δεδομένα μπορούν να ενσωματωθούν, όπως το καταλαβαίνω.
Απολύτως. Όποιος παίρνει πραγματικές αποφάσεις χρησιμοποιεί δεδομένα από πολλές πηγές, που παράγονται από πολλά είδη οργανισμών, και αυτό γίνεται εμπόδιο. Τείνουμε να χρησιμοποιούμε τις πλάτες φακέλων για να το κάνουμε αυτό και οι άνθρωποι πρέπει να βάζουν τα δεδομένα σε υπολογιστικά φύλλα, τα οποία προετοιμάζουν με πολύ κόπο. Κατά κάποιο τρόπο, ο Σημασιολογικός Ιστός μοιάζει κάπως με όλες τις βάσεις δεδομένων εκεί έξω ως μία μεγάλη βάση δεδομένων. Είναι δύσκολο να φανταστεί κανείς τη δύναμη που θα έχουμε όταν διατίθενται τόσα διαφορετικά είδη δεδομένων.
Μου φαίνεται ότι είμαστε «πνιγμένοι» με δεδομένα και αυτός μπορεί να είναι ένας καλός τρόπος για να μπορούμε να βρούμε τα δεδομένα που χρειαζόμαστε.
Όταν μπορούμε να αντιμετωπίζουμε κάτι ως δεδομένα, το ερώτημά σας μπορεί να είναι πολύ πιο ισχυρό. [14Στμ: Εννοεί όταν υπάρχει η δυνατότητα να οργανωθούν τα δεδομένα (data) ως τέτοια και όχι απλά ως εγγραφές σε μια βάση δεδομένων. Δηλαδή, όταν αποκτήσουν και την σημασιολογική τους διασύνδεση. Τότε τα ερωτήματα αναζήτησης πληροφοριών, θα είναι πιο ισχυρά.]
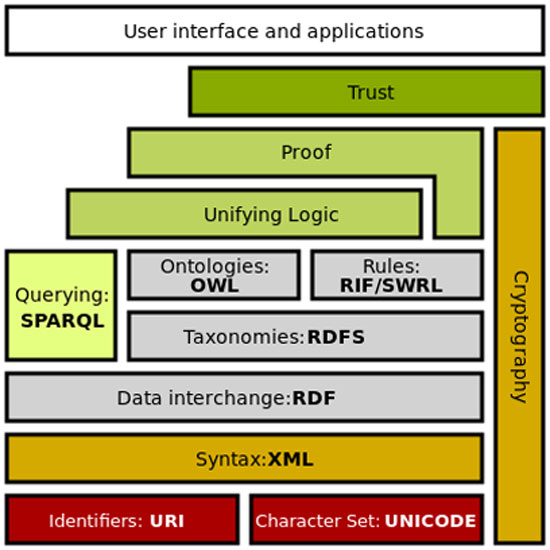 Η δομή των προτύπων και τεχνολογιών που συνθέτουν το Semantic Web
Η δομή των προτύπων και τεχνολογιών που συνθέτουν το Semantic WebΣτην ομιλία σας στο Princeton πέρυσι, είπατε ότι ίσως είχατε κάνει λάθος στην ονομασία του ως «Σημασιολογικός Ιστός». Πιστεύετε ότι το όνομα μπερδεύει μερικούς ανθρώπους;
Δεν νομίζω ότι είναι πολύ καλό όνομα, αλλά έχουμε κολλήσει με αυτό τώρα. Η λέξη σημασιολογία χρησιμοποιείται από διαφορετικές ομάδες και σημαίνει διαφορετικά πράγματα. Αλλά τώρα οι άνθρωποι καταλαβαίνουν ότι ο Σημασιολογικός Ιστός είναι ο Ιστός Δεδομένων. Νομίζω ότι θα μπορούσαμε να το έχουμε ονομάσει Ιστό Δεδομένων (Data Web). Θα ήταν απλούστερο. Αντιμετωπίσα πολλά προβλήματα με το να ονομάσω τον Παγκόσμιο Ιστό «www» γιατί ήταν τόσο μακρύ και δύσκολο για να το προφέρεις. Στο τέλος, όταν οι άνθρωποι καταλαβαίνουν τι είναι, καταλαβαίνουν ότι συνδέει όλες τις εφαρμογές μαζί ή τους δίνει πρόσβαση σε δεδομένα σε ολόκληρη την εταιρεία, όταν βλέπουν μερικές γενικές εφαρμογές του Σημασιολογικού Ιστού.
Μερικές από τις πρώτες εργασίες με τον Σημασιολογικό Ιστό φαίνεται να έχουν γίνει από κυβερνητικές υπηρεσίες όπως η Υπηρεσία Προχωρημένων Έργων Άμυνας (DARPA) και η Εθνική Διοίκηση Αεροναυτικής & Διαστήματος (NASA). Γιατί πιστεύετε ότι η κυβέρνηση έχει υιοθετήσει νωρίς αυτήν την τεχνολογία;
Κατανοώ ότι η DARPA είχε τα δικά της σοβαρά προβλήματα με τεράστιες ποσότητες δεδομένων από όλες τις διαφορετικές πηγές για κάθε είδους πράγματα. Έτσι, είδαν σωστά τον Σημασιολογικό Ιστό ως κάτι που στοχεύει άμεσα στην επίλυση των προβλημάτων που είχαν σε μεγάλη κλίμακα. Γνωρίζω ότι η DARPA χρηματοδότησε επίσης στη συνέχεια μέρος της αρχικής ανάπτυξης αυτής της τεχνολογίας.
Έχετε αναφέρει την ιδέα ότι ο Σημασιολογικός Ιστός θα διευκολύνει την ανακάλυψη θεραπειών για ασθένειες. Πώς θα το κάνει αυτό;
Λοιπόν, όταν μια φαρμακευτική εταιρεία εξετάζει μια ασθένεια, παίρνουν τα συγκεκριμένα συμπτώματα που συνδέονται με συγκεκριμένες πρωτεΐνες μέσα σε ένα ανθρώπινο κύτταρο που μπορεί να οδηγήσουν σε αυτά τα συμπτώματα. Έτσι, η τέχνη της εύρεσης του φαρμάκου είναι η εύρεση της χημικής ουσίας που θα επηρεάσει τα κακά πράγματα που συμβαίνουν και θα ενθαρρύνει τα καλά πράγματα που συμβαίνουν μέσα στο κύτταρο, η οποία περιλαμβάνει την κατανόηση της γενετικής και όλων των συνδέσεων μεταξύ των πρωτεϊνών και των συμπτωμάτων της νόσου.
Απαιτεί επίσης να εξετάσουμε όλες τις άλλες συνδέσεις, αν υπάρχουν ομοσπονδιακοί κανονισμοί σχετικά με τη χρήση της πρωτεΐνης και πώς έχει χρησιμοποιηθεί προηγουμένως. Έχουμε κυβερνητικές κανονιστικές πληροφορίες, δεδομένα κλινικών δοκιμών, δεδομένα γονιδιωματικής και δεδομένα πρωτεομικής που βρίσκονται όλα σε διαφορετικά τμήματα και διαφορετικά λογισμικά. Ένας επιστήμονας που τελεί αυτή τη δημιουργική διαδικασία ανταλλαγής ιδεών, για να βρει κάτι που θα μπορούσε ενδεχομένως να θεραπεύσει την ασθένεια, πρέπει να κρατήσει τα πάντα στο κεφάλι του ταυτόχρονα ή να μπορεί να εξερευνήσει όλους αυτούς τους διαφορετικούς άξονες με έναν συνδεδεμένο τρόπο. Ο Σημασιολογικός Ιστός είναι μια τεχνολογία που έχει σχεδιαστεί για να κάνει αυτό ακριβώς - για να ανοίξει τα όρια μεταξύ των σιλό, να επιτρέψει στους επιστήμονες να εξερευνήσουν τις υποθέσεις, να δουν πώς συνδέονται τα πράγματα σε νέους συνδυασμούς που δεν είχαν ονειρευτεί ποτέ πριν.
Ο Σημασιολογικός Ιστός καθιστά πολύ πιο εύκολο να βρεθούν και να συσχετισθούν πληροφορίες για σχεδόν οτιδήποτε, συμπεριλαμβανομένων των ανθρώπων. Τι θα συμβεί αν αυτές οι πληροφορίες φτάσουν σε λάθος χέρια; Υπάρχει κάτι που μπορεί να γίνει για τη διαφύλαξη της ιδιωτικότητας;
Εδώ στο MIT, κάνουμε έρευνα και οικοδόμηση συστημάτων που αναγνωρίζουν τα κοινωνικά ζητήματα. Έχουν επίγνωση των περιορισμών απορρήτου, των κατάλληλων χρήσεων των πληροφοριών. Πιστεύουμε ότι είναι σημαντικό να δημιουργήσουμε συστήματα που θα βοηθήσουν να γίνεται το σωστό, αλλά επίσης δημιουργούμε συστήματα που, όταν λαμβάνουν δεδομένα από πολλές, πολλές πηγές και τα συνδυάζουν και επιτρέπουν να καταλήξουμε σε ένα συμπέρασμα, είναι διαφανή υπό την έννοια ότι μπορούμε να τα ρωτήσουμε σε τι βασίστηκε η απόφασή τους και ότι μπορούμε να επιστρέψουμε για να ελέγξουμε αν είναι πράγματα κατάλληλα για χρήση και αν νιώθουμε ότι είναι αξιόπιστα.
Η ανάπτυξη των προτύπων του Σημασιολογικού Ιστού χρειάστηκε χρόνια. Χρειάστηκε τόσος χρόνος γιατί ο Σημασιολογικός Ιστός είναι τόσο περίπλοκος;
Ο Σημασιολογικός Ιστός δεν είναι εγγενώς περίπλοκος. Η γλώσσα του Σημασιολογικού Ιστού, στην καρδιά της, είναι πολύ, πολύ απλή. Έχει να κάνει με τις σχέσεις μεταξύ των πραγμάτων.
 Ελεύθερη μετάφραση: Για να δουλέψει το Σημασιολογικό Διαδίκτυο πρέπει η ζωή να κωδικοποιηθεί στην γλώσσα της μηχανής
Ελεύθερη μετάφραση: Για να δουλέψει το Σημασιολογικό Διαδίκτυο πρέπει η ζωή να κωδικοποιηθεί στην γλώσσα της μηχανήςΈνα (νέο) παράδειγμα
Το «όραμα» του Berners-Lee, για την διευκόλυνση στην εύρεση θεραπειών μέσω των sematics, είναι ήδη πραγματικότητα. Η περίπτωση της Astra Zeneca είναι ένα παράδειγμα όπου τα σημασιολογικά δεδομένα γίνονται πράξη σε έρευνες για νέα φάρμακα και θεραπείες. Μεταφράζουμε από σχετικό έγγραφο:
Για τις ανάγκες της συλλογής πληροφοριών από ένα ευρύ φάσμα πηγών βιοϊατρικών δεδομένων, η Astra Zeneca βρήκε την λύση στα Linked Data. Οι ερευνητές της εταιρείας χρειάστηκαν έναν μηχανισμό που θα τους επιτρέψει να εξορύξουν όλα τα δεδομένα που είναι διασκορπισμένα μεταξύ διαφορετικών σχετικών πόρων και να εντοπίσουν ορατές (άμεσες) και αόρατες (απόμακρες) σχέσεις μεταξύ βιοϊατρικών στοιχείων που μελετήθηκαν κατά τη διάρκεια της φαρμακευτικής έρευνας.
Δημιουργώντας μια πλατφόρμα αναζήτησης διαδραστικών σχέσεων, που ονομάζεται Linked Life Data, η βιο-φαρμακευτική εταιρεία μπόρεσε να αποκτήσει υψηλής ποιότητας ερευνητικά δεδομένα από τα μη δομημένα έγγραφά τους. Η πλατφόρμα ενσωμάτωσε περισσότερους από 25 πόρους δεδομένων και συνδύασε περισσότερα από 17 διαφορετικά βιοϊατρικά αντικείμενα: γονίδια, πρωτεΐνες, μοριακές λειτουργίες, βιολογικές διεργασίες, μοριακές αλληλεπιδράσεις, εντοπισμό κυττάρων, οργανισμούς, όργανα / ιστούς, κυτταρικές σειρές, τύπους κυττάρων, ασθένειες, συμπτώματα, φάρμακα, παρενέργειεςφαρμάκων, δημοσιεύσεις, κλπ.
Η πλατφόρμα Linked Life Data ήταν σε θέση να εντοπίσει σαφείς σχέσεις μεταξύ των στοιχείων, κατηγοριοποιώντας τα σε οντολογίες. Εξόρυξε επίσης μη δομημένα δεδομένα για τον εντοπισμό σχέσεων που δεν φαίνονται με μια πρώτη ανάγνωση. Ήταν μια τεράστια βοήθεια για τους ερευνητές, ώστε να έχουν μια γενική εικόνα ως προς τη δημιουργία ή την επέκταση μιας συγκεκριμένης θεωρίας, τη δοκιμή υποθέσεων και την πραγματοποίηση ενημερωμένων ισχυρισμών σχετικά με το ποιες σχέσεις είναι αιτιώδεις και για το πώς ακριβώς είναι αιτιώδης η συνάφεια.
 Πρότυπα τριγώνων RDF της AZ
Πρότυπα τριγώνων RDF της AZΑντί επιλόγου
Η απόσταση ανάμεσα στο να αποδείξει ένας άνθρωπος ότι δεν είναι ρομπότ και στο να αποδείξει μια μηχανή ότι δεν είναι ρομπότ, μικραίνει. Όχι γιατί οι μηχανές γίνονται έξυπνες, αλλά γιατί η ανθρώπινη σκέψη και το ανθρώπινο σώμα τεμαχίζονται, ταξινομούνται, «χρονομετρούνται» και μεταφράζονται, ώστε να μπορούν γίνουν επεξεργάσιμες από την μηχανή. Αυτή η διαδικασία δεν έχει ως αποτέλεσμα την ανάπτυξη μιας «ανθρώπινης μηχανής», αλλά μιας «μηχανοποιημένης ανθρωπινότητας». Και έχει την γενεαλογία της.
Θα κλείσουμε με ένα μικρό απόσπασμα από τα τετράδια για εργατική χρήση νο 3, «η μηχανοποίηση της σκέψης», παραπέμπτοντας εκεί για μια ευρύτερη κριτική προσέγγιση:
Η εννόηση της γλώσσας ως συστήματος είναι ένα είδος “αλλαγής παραδείγματος” στη γλωσσολογία, που προτείνει και προχωράει ο Saussure στο δεύτερο μισό της πρώτης δεκαετίας του 20ου αιώνα. Όμως η ιδέα του “συστήματος” προέρχεται από τις θετικές επιστήμες! Έχει ήδη καθιερωθεί στη χημεία, στη βιολογία και στη φυσική του 19ου αιώνα: στη θερμοδυναμική, στη μηχανική…
Η τολμηρή κίνηση του Saussure είναι λοιπόν ότι παίρνει μια ιδέα δοκιμασμένη ήδη είτε με μηχανική είτε με οργανική χροιά, την ιδέα του συστήματος, και την εφαρμόζει σε “κάτι” (την ανάλυση της γλώσσας) που ως τότε είχε μια ιστορικο-αναλυτική κατεύθυνση. Ο Saussure (στα “μαθήματα γενικής γλωσσολογίας”) είναι ενθουσιασμένος μ’ αυτήν την μετάθεση. Και κατηγορηματικός:
«… Μια γλώσσα αποτελεί ένα σύστημα… το σύστημα αυτό είναι ένας περίπλοκος μηχανισμός· δεν μπορεί κανείς να τη δαμάσει παρά μόνο με τη σκέψη· κι αυτοί οι ίδιοι που κάνουν καθημερινά χρήση αυτού του μηχανισμού, τον αγνοούν βαθύτατα...»
Η πιο πάνω θέση είναι βασική και αφετηριακή στον τρόπο που ο Saussure προτείνει την επιστημονική ανάλυση των γλωσσών. Και είναι βαθιά Ταιηλορική, ακόμα κι αν δεν συνάντησε και δεν άκουσε ποτέ τίποτα για τον (σύγχρονό του) Frederick Winslow Taylor:
α) η γλώσσα είναι μηχανισμός και μάλιστα περίπλοκος·
β) αυτόν τον “περίπλοκο μηχανισμό” ΔΕΝ τον γνωρίζουν όσοι τον “χρησιμοποιούν” (μιλώντας ή γράφοντας)!
Χωρίς ίχνος υπερβολής θα λέγαμε ότι ο Saussure είναι ο πρώτος (θα ακολουθήσουν πολλοί άλλοι) που αντιλαμβάνεται τον επιστήμονα εαυτό του, τον επιστήμονα γλωσσολόγο, σαν μ η χ α ν ι κ ό τ η ς γ λ ώ σ σ α ς. Το γλωσσικό σύστημα ήταν μια σύλληψη που σήμερα δείχνει κοινότοπη, αλλά στον καιρό της ήταν καινοτόμα όσο και εντυπωσιακή. Κι αυτό γιατί απ’ την στιγμή που η γλώσσα εννοείται σαν σύστημα, τα “συστατικά του συστήματος” (οι λέξεις, τα νοήματα, οι εκφράσεις), σχεδόν άπειρα από ποσοτική άποψη, θα πρέπει να “αναλυθούν” με έναν τρόπο ποιοτικό· αν πρόκειται ο “μηχανικός της γλώσσας” να “δαμάσει τον μηχανισμό”. Θα χρειαστεί, γι’ αυτό, να εφεύρει καινούρια αναλυτικά εργαλεία…
Wintermute
Σημειώσεις
1 - Το Turing test είναι μια διαδικασία με την οποία εξετάζεται το κατά πόσο ένας υπολογιστής μπορεί να προσομοιώσει την ανθρώπινη νοημοσύνη. Το τεστ γίνεται με την μορφή γραπτών ερωτο-απαντήσεων μεταξύ ενός ανθρώπου και δύο κρυμμένων «συνομιλιτών», ενός ανθρώπου και ενός υπολογιστή. Η αξιολόγηση γίνεται στην βάση της αναγνώρισης από τον πρώτο του ποιός είναι ο άνθρωπος και ποιός η μηχανή.
[ επιστροφή]
2 - https://en.wikipedia.org/wiki/Knowledge_representation_and_reasoning
[ επιστροφή]
3 - One step closer to intertwingularity: Semantic Metadata - https://www.ontotext.com/blog/semantic-metadata/
[ επιστροφή]
4 - Η Διαλειτουργικότητα (Intertwingularity) είναι ένας όρος που επινοήθηκε από τον Ted Nelson για να εκφράσει την πολυπλοκότητα των αλληλεπιδράσεων στην ανθρώπινη γνώση. Ο Nelson έγραψε στο Computer Lib / Dream Machines (Nelson 1974): «Όλα είναι βαθειά διασυνδεδεμένα. Με μια έννοια δεν υπάρχουν καθόλου "υποκείμενα". Υπάρχει μόνο η γνώση, αφού οι διασυνδέσεις μεταξύ των μυριάδων θεμάτων αυτού του κόσμου απλά δεν μπορούν να διαχωριστούν ξεκάθαρα.»
[ επιστροφή]
5 - O Thomas Gruber είναι επίσης και ο συν-ιδρυτής της εταιρείας Siri Inc, που κατασκεύασε την ψηφιακή προσωπική βοηθό Siri, η οποία αγοράστηκε από την Apple to 2010 και υπάρχει πλέον σε κάθε συσκευή της. Στο πλούσιο βιογραφικό του μπορεί να βρει κανείς την συνεισφορά του στο τομέα της τεχνητής νοημοσύνης και της διεπαφής με τον χρήστη, την συνεργασία του με πολλές εταιρείες καθώς και με την DARPA. Τα τελευταία χρόνια προωθεί την ιδέα του περί «ανθρωπιστικής τεχνητής νοημοσύνης» (Humanistic AI). Για περισσότερα δείτε και την σχετική ομιλία του στο TED.
[ επιστροφή]
6 - Ontology, by Tom Gruber, in the Encyclopedia of Database Systems, Ling Liu and M. Tamer Özsu (Eds.), Springer-Verlag, 2009.
[ επιστροφή]
7 - Naïve physics: η λαϊκή/απλοποιημένη φυσική είναι η ανεκπαίδευτη ανθρώπινη αντίληψη για τα βασικά φυσικά φαινόμενα. Στον τομέα της τεχνητής νοημοσύνης, η μελέτη της απλοποιημένης φυσικής αποτελεί μέρος της προσπάθειας τυποποίησης της κοινής γνώσης των ανθρώπων.
[ επιστροφή]
8 - Knowledge-based system: ένα πρόγραμμα υπολογιστή που αιτιολογεί και χρησιμοποιεί μια βάση γνώσεων για την επίλυση σύνθετων προβλημάτων.
[ επιστροφή]
9 - Toward principles for the design of ontologies used for knowledge sharing (https://tomgruber.org/writing/onto-design.htm)
[ επιστροφή]
10 - Web Ontology Language (OWL): Η Γλώσσα Οντολογίας Ιστού είναι μια οικογένεια γλωσσών αναπαράστασης γνώσης για την συγγραφή οντολογιών στον Σημασιολογικό Ιστό (Semantic Web).
[ επιστροφή]
11 - Το οποίο προϋποθέτει και τις κρίσιμες υποδομές για μια ολοκληρωμένη dato-ποίηση: έξυπνες συσκευές παντού, internet των πραγμάτων (Internet of Things – IoT) και ικανό δίκτυο για να «σηκώσει» τον όγκο (5G, 6G κοκ).
[ επιστροφή]
12 - Q&A with Tim Berners-Lee - The inventor of the Web explains how the new Semantic Web could have profound effects on the growth of knowledge and innovation [Bloomberg - April 9 2007]
[ επιστροφή]
13 - Στμ: Τα σιλό είναι κατασκευές που χρησιμοποιούνται για την τροφοδοσία (φόρτωση, εκφόρτωση) και την αποθήκευση χύδην στερεών υλικών. Ο όρος σιλό προέρχεται από το γαλλικό silo, το οποίο με τη σειρά του από το ισπανικό silo, «υπόγεια αποθήκη», με πιθανή προέλευση από το λατινικό sirus, το οποίο προέρχεται από το αρχαίο ελληνικό σιρός, «δοχείο ή λάκκος για φύλαξη σιτηρών». Στο παρόν χρησιμοποιείται μεταφορικά για ψηφιακούς χώρους αποθήκευσης.
[ επιστροφή]
14 - Στμ: Εννοεί όταν υπάρχει η δυνατότητα να οργανωθούν τα δεδομένα (data) ως τέτοια και όχι απλά ως εγγραφές σε μια βάση δεδομένων. Δηλαδή, όταν αποκτήσουν και την σημασιολογική τους διασύνδεση. Τότε τα ερωτήματα αναζήτησης πληροφοριών, θα είναι πιο ισχυρά.
[ επιστροφή]