
#19 - 10/2020
- 01001100110119 – cyborg
- Τα σκυλάκια του Pavlok
- Από τις μεταλλάξεις στον "αναπρογραμματισμό": η προέλαση της γενετικής μηχανικής
- Γυμνός θάνατος: χορεύοντας στους ρυθμούς του κρατικού Danse Macabre
- Human-X: the next generation
- Metadata: τα data στο μικροσκόπιο
- Τεχνολογίες που μας αρρωσταίνουν
- Τα ρομπότ δεν μας παίρνουν τις δουλειές. Γίνονται οι επιστάτες μας!
- Τα data στο γκισέ της τράπεζας
- Τίνος η υγεία; (μα της 4ης βιομηχανικής επανάστασης!)
- Τηλε-εργασία: τα μετα-δεδομένα στην υπηρεσία μέτρησης της παραγωγικότητας της εργασίας
- bytes & genes
Metadata: τα data στο μικροσκόπιο

Το εκτιμώμενο μέγεθος του ψηφιακού σύμπαντος στα τέλη του 2020, σύμφωνα με το παγκόσμιο οικονομικό φόρουμ, θα είναι 44 zettabytes (44 πεντάκις εκατομύρια bytes)· 40 φορές περισσότερα bytes από όσα αστέρια υπάρχουν στον ορατό σύμπαν. Κάθε μέρα στέλνονται 500 εκ. τιτιβίσματα, 294 δις. emails, 4 petabytes (4 τετράκις εκατομύρια bytes) data παράγονται στο facebook, 4 terabytes (4 δισεκατομύρια bytes) data παραγονται από συνδεδεμένα αυτοκίνητα, 65 δις. μηνύματα ανταλλάσονται στο whatsapp και γίνονται 5 δις αναζητήσεις. Η εκτίμηση είναι ότι μέχρι το 2025 θα παράγονται 463 exabytes (463 τετράκις bytes) πληροφορίας κάθε μέρα.
Με μια γρήγορη αναζήτηση στο διαδίκτυο, οι στατιστικές, οι μετρήσεις και οι εκτιμήσεις που βρήκαμε για τον “όγκο” των data ήταν αρκετές για να γεμίσουν αρκετές από αυτές τις σελίδες με πολλά μηδενικά. Πόσοι χρήστες του internet υπάρχουν και πόσο αυξάνονται; Τί παράγουμε κάθε χρόνο, κάθε μήνα, κάθε μέρα, κάθε λεπτό; Από πού παράγονται; Πώς παράγονται; Μηδενικά που προκαλούν δέος, ειδικά όταν συγκρίνονται με την ύλη, πχ τα αστέρια. Κάπου αλλού βρήκαμε ότι αν ένα byte ήταν ένα γαλόνι νερού (περίπου 3,7 λίτρα) θα χρειάζοταν 2 δευτερόλεπτα, με τον υπάρχον ρυθμό παραγωγής data, για να γεμίσει ένα μέσο σπίτι. Τί εννοεί με μέσο σπίτι ο ποιητής δεν το διευκρινίζει, αλλά στο απαραίτητα αποβλακωτικό σχεδιάκι δίπλα, υπήρχε ένα σπίτι σαν αυτό που ζωγραφίζαμε στο νηπιαγωγείο: ένα τετράγωνο με ένα τρίγωνο από πάνω, μάλλον διώροφο.
Υπάρχει η τάση να συγκρίνεται η πληροφορία με κάτι υλικό· σαν να προσπαθεί να στερεωθεί η ιδεολογία που την περιβάλλει με κάτι το οικείο. Τί είναι όμως η πληροφορία και τα data; Έχουμε αναφερθεί στο παρελθόν [1Τι είναι τα data και σε ποιόν ανήκουν; - Cyborg #13, Οκτώβρης 2018]:
Τα data (και η γενικευμένη, καθολική data-ποίηση) είναι το καινούργιο “χρυσάφι”, η καινούργια ατέλειωτη πρώτη ύλη του βιοπληροφορικού καπιταλισμού. Η 4η βιομηχανική επανάσταση στηρίζεται παντού στα data, στα δεδομένα: στη συγκέντρωση, στη διαχείριση και στην επεξεργασία τους, στην καπιταλιστική αξιοποίησή τους. Όλα τα αναγγελμένα θαύματα της 4ης βιομηχανικής επανάστασης, απ’ το internet of things μέχρι το cloud, απ’ την εξατομικευμένη ιατρική μέχρι την καθολική μεσολάβηση / μηχανοποίηση της καθημερινής ζωής, στηρίζονται στα ή περνάνε μέσα από τα data.
[…]
Όσο κι αν φαίνεται παράξενο ΔΕΝ υπάρχει συγκεκριμένος ορισμός τι είναι “δεδομένο”!!! Θα μπορούσε κανείς να υποθέσει ότι πρόκειται για την “μονάδα πληροφορίας” - αλλά έτσι γίνεται μια μετάθεση ορισμών απ’ το “δεδομένο” στην “πληροφορία”, για την οποία επίσης ΔΕΝ υπάρχει συγκεκριμένος και ακριβής ορισμός!!
Δεν είναι καθόλου τολμηρό, αντίθετα είναι ιστορικά ακριβές, να υποστηρίξει κανείς ότι τα data (στον πληθυντικό) είναι μια πολύ πρόσφατη κατασκευή σαν “έννοια”, ένα είδος μετα-εννόησης άμεσα και οργανικά σχετισμένο με την σύλληψη και την λειτουργία των ηλεκτρονικών υπολογιστών. Μια συγκεκριμένη μαθηματική θεωρία που συνέλαβε την λειτουργία και την χρησιμότητα της μηχανικής διευθέτησης “αποφάνσεων” ναι ή όχι (με πιο διάσημο δημιουργό τον αμερικάνο μαθηματικό Claude Shannon) είχε ανάγκη από ονόματα (και θεωρία) για την λειτουργία αυτών των διακοπτών δύο θέσεων (“ναι” ή “όχι”). Χωρίς υπερβολή η ιδέα περί data γέννησε τους ηλεκτρονικούς υπολογιστές και όχι το ανάποδο: οτιδήποτε μπορεί να αναχθεί στο on ή off (της ροής ηλεκτρικού ρεύματος) είναι δεδομένο (και με ορισμένες προϋποθέσεις πληροφορία).
Αν και η έννοια της πληροφορίας είναι πιο διευρημένη, αυτή των δεδομένων/data σχετίζεται αποκλειστικά με τους υπολογιστές. Η πρώτη χρήση του όρου το 1946 υποδήλωνε “επικοινωνίσιμες και αποθηκεύσιμες πληροφορίες υπολογιστή”. Στα λατινικά η λέξη data είναι ο πληθυντικός της λέξης datum: αντικείμενο, αλλά η συνηθισμένη χρήση της στα αγγλικά είναι σε ενικό που δηλώνει το αμέτρητο, όπως η βροχή ή η άμμος· σαν φάρσα της ιστορίας για κάτι που έχει ως κύριο σκοπό την μέτρηση.
Το τοπίο είναι αρκετά θολό όταν προσπαθούμε να συλλάβουμε την ιδέα της πληροφορίας και των δεδομένων/data. Οι πρώτες αναφορές μάλλον είναι σε προτάσεις που περιγράφουν κάποιο αντικείμενο· μετά σκεφτόμαστε κάποιο γεγονός ως πληροφορία και ίσως λίγο αργότερα φανταστούμε μια εικόνα, έναν ήχο ή πιο σπάνια μια γεύση ή μια μυρωδιά. Κάπου ενδιάμεσα παρεμβάλλονται η γνώση, η αντίληψη και οι διαφορετικές ερμηνείες. Η απομόνωση αυτών των πληροφοριών από τις παραπάνω παρεμβολές και γενικά από την ανθρώπινη αντίληψη/ερμηνεία/κατανόηση ίσως μας φέρνει πιο κοντά σε μια απάντηση για το τί είναι πληροφορία/data. Ο σκοπός της είναι να γίνεται αντιληπτή/ερμηνεύσιμη/κατανοητή από την μηχανή και όχι από την ανθρώπινη εμπειρία· εκείνη έρχεται σε δεύτερο χρόνο για να προσπαθήσει να αντιληφθεί/ερμηνεύσει/κατανοήσει την πλέον μεσολαβημένη πληροφορία.
Αν λοιπόν η πληροφορία/data είναι η μεταφρασμένη ανθρώπινη εμπειρία στην γλώσσα της μηχανής, η συλλογή της σε αποθήκες (βάσεις δεδομένων και data centers) προς επεξεργασία είναι η λειτουργία από την οποία προκύπτουν τα big data. Είναι σημαντική αυτή η επισήμανση: τα big data είναι απλά αυτή η τεράστια συλλογή των data, παρόλο που στην καθομιλουμένη υποννοείται και η επεξεργασία/διαχείρισή τους. Οι ειδικοί προς το παρόν καμαρώνουν για τις μεγάλες αποθήκες δεδομένων που έχουν συγκεντρώσει και αυξάνουν συνεχώς, ενώ η διαδικασία της επεξεργασίας τους υστερεί ακόμα σε σχέση με τον όγκο που έχουν στην διάθεσή τους. Οι έξυπνοι αλγόριθμοι μηχανικής μάθησης (machine learning) και οι τεχνητές νοημοσύνες προπονούνται αδιάκοπα για να εκπληρώσουν τις θαυμαστές υποσχέσεις των ειδικών.
Η επεξεργασία όλων αυτών των πληροφοριών που φανταζόμαστε ως data, όπως τα μηνύματα που ανταλλάσσονται, τις αναζητήσεις και τις επισκέψεις σε ιστο-σελίδες, τις φωτογραφίες και τα βίντεο που δημοσιεύονται, είναι στην ουσία και κατά κύριο λόγο η επεξεργασία του πλαισίου τους, και κατά δεύτερο λόγο το ίδιο το περιεχόμενο – όπως τουλάχιστον θα το αντιλαμβανόταν/ερμήνευε/κατανοούσε η ανθρώπινη εμπειρία. Η έκφραση του προσώπου για παράδειγμα, σε συνδυασμό με τον φωτισμό, την τοποθεσία, την ημερομηνία, το πού δημοσιεύτηκε η φωτογραφία, αν υπάρχουν και άλλα άτομα, η ανάλυση των pixel , ακόμα και ο τρόπος που κράταγε ο φωτογράφος το κινητό είναι οι χρήσιμες για την μηχανή πληροφορίες· η μηχανή δεν θέλει να θυμηθεί, θέλει να αναλύσει και να αποθηκεύσει. Αυτές οι πληροφορίες/data που θέλουν να φτάσουν μέχρι την απειρο-ελάχιστη κλίμακα της ύπαρξης και αποτελούν την πρώτη ύλη του νέου παραδείγματος, ονομάζονται metadata στην γλώσσα των ειδικών.

data για τα data
Ο ορισμός των metadata είναι: data για τα data· πληροφορίες που περιγράφουν ή/και συνοψίζουν άλλες πιο “κεντρικές” πληροφορίες, που θα μπορούσαν να χαρακτηριστούν ως “περιεχόμενο”, με σκοπό την πιο εύκολη αναζήτηση και επεξεργασία τους. Η πρώτη περιγραφή αποδίδεται στους David Griffel και Stuart McIntosh του MIT, το 1967: “Συνοπτικά, έχουμε δηλώσεις των υποκειμενικών περιγραφών των δεδομένων σε μια αντικειμενική γλώσσα, καθώς και διακριτικούς κωδικούς για αυτά τα δεδομένα. Επίσης έχουμε δηλώσεις σε μια μετα-γλώσσα που περιγράφει τις σχέσεις των δεδομένων και τους μετασχηματισμούς τους, οι οποίες είναι σχέσεις μεταξύ κανόνα και δεδομένων”. Στην αρχική τους μορφή τα μετα-δεδομένα ήταν οι κατάλογοι στις βιβλιοθήκες, που περιείχαν όλες τις πληροφορίες των βιβλίων εκτός του περιεχομένου/κειμένου. Στην πορεία, με τα πρώτα βήματα της ψηφιοποίησης στα τέλη των 80s, αυτοί οι κατάλογοι μπήκαν σε σκληρούς δίσκους και έγιναν βάσεις δεδομένων, ενώ παράλληλα εμφανίστηκαν και νέες ευκαιρίες για καταλόγους/βάσεις δεδομένων.
Ξεχωριστά πρότυπα περιγραφής ισχύουν για τα διάφορα είδη δεδομένων (πχ, άλλο πρότυπο χρησιμοποιείται για μια συλλογή σε μουσείο και άλλη για ψηφιακά αρχεία ήχου ή εικόνας, για τα websites ή τα ιατρικά δεδομένα). Μερικές από αυτές τις περιγραφές μπορεί να είναι: με ποιό μέσο/πρόγραμμα δημιουργήθηκαν τα data, ποιός είναι ο σκοπός τους, η ημερομηνία και η ώρα δημιουργίας, ποιός είναι ο δημιουργός, σε ποιό σημείο μέσα στο σύστημα αρχείων ή/και δικτύου είναι αποθηκευμένα, ποιά πρότυπα χρησιμοποιούν, ποιό είναι το μέγεθος και η ποιότητα των δεδομένων, ποιές είναι οι πηγές και ποιά η διαδικασία με την οποία δημιουργήθηκαν.
Τα μετα-δεδομένα χωρίζονται σε διάφορους τύπους όπως τα περιγραφικά μετα-δεδομένα που χρησιμοποιούνται στην αναζήτηση και αναγνώριση του περιεχομένου (πχ τίτλος, περίληψη, συγγραφέας, λέξεις κλειδιά), τα δομικά μετα-δεδομένα που υποδεικνύουν τον τρόπο με τον οποίο τα σύνθετα αντικείμενα συγκεντρώνονται (πχ η διάταξη των σελίδων που σχηματίζουν τα κεφάλαια σε ένα βιβλίο, ο τύπος του αντικειμένου, οι διαφορετικές εκδόσεις/εκδοχές και άλλα χαρακτηριστικά του ψηφιακού υλικού), τα διαχειριστικά μετα-δεδομένα (πχ δικαιώματα, τόπος και χρόνος δημιουργίας), τα μετα-δεδομένα αναφοράς σχετικά με το περιεχόμενο και την ποιότητα των στατιστικών δεδομένων, τα στατιστικά μετα-δεδομένα που περιγράφουν τις διαδικασίες που συλλέγουν, επεξεργάζονται και παράγουν στατιστικά δεδομένα, και τα λοιπά...
Οι διάφορες δραστηριότητες στον κυβερνοχώρο περιλαμβάνουν και αφήνουν “πίσω” τους αρκετά τέτοια “ίχνη” πληροφοριών. Μερικά παραδείγματα:
Η αποστολή ενός email, περιλαμβάνει εκτός από το ίδιο το κείμενο: το όνομα, την διεύθυνση ηλεκτρονικού ταχυδρομείου και την ιντερνετική διεύθυνση IP, του αποστολέα· το όνομα και την διεύθυνση ηλεκτρονικού ταχυδρομείου του παραλήπτη· πληροφορίες για την διαδρομή που ακολούθησε το email στους διάφορους ενδιάμεσους servers· την ημερομηνία, ώρα και ζώνη ώρας· έναν μοναδικό κωδικό ταυτοποίησης του email και όσων σχετίζονται με αυτό· ο τύπος του περιεχομένου και η κωδικοποίησή του· εγγραφές για το πότε ο χρήστης έκανε login/logout στον λογαριασμό του· οι “επικεφαλίδες” (headers [2Ένα κομμάτι κώδικα που υπάρχει σε κάθε email και έχει μια σύνοψη τέτοιων μετα-πληροφοριών.]) των email· αν υπάρχουν άλλοι παραλήπτες, σε cc ή bcc· αν υπάρχουν συνημμένα αρχεία, τί τύπου, μεγέθους κλπ· αν το email υπάγεται σε κάποια κατηγορία σύμφωνα με μια ενδεχόμενη κατηγοριοποίηση του χρήστη στα email του· το θέμα/τίτλος του email· η κατάσταση του email, αν παραδόθηκε, πότε παραδόθηκε, αν είναι απάντηση σε άλλο email κλπ· αν υπάρχει αναφορά παράδοσης.
Σε μια τηλεφωνική συνομιλία, τα μετα-δεδομένα που παράγονται περιλαμβάνουν: τους αριθμούς τηλεφώνου που επικοινωνούν· τους μοναδικούς σειριακούς αριθμούς των δύο τηλεφώνων· την ημερομηνία και την ώρα της κλήσης· την διάρκεια της κλήσης· την τοποθεσία των δύο τηλεφώνων· τους αριθμούς των sim καρτών των κινητών, κ.α.
Τα metadata μιας φωτογραφίας, μεταξύ άλλων, είναι: το μέγεθός της σε bytes· οι διαστάσεις, η ανάλυση και ο προσανατολισμός· η ταχύτητα του κλείστρου,το εστιακό μήκος και ο τύπος του φλάς· ημερομηνία και τοποθεσία δημιουργίας· περιγραφές για το τί δείχνει· πληροφορίες δικαιωμάτων χρήσης· η μάρκα και το μοντέλο της κάμερας· αν έχει υποστεί επεξεργασία και πολλά ακόμα [3Έναν (μάλλον) εξαντλητικό κατάλογο των metadata που μπορεί να έχει μια φωτογραφία μπορείτε να δείτε εδώ: https://www.photometadata.org/META-Resources-Field-Guide-to-Metadata].
Στα social media τύπου facebook και twitter, κάποια από τα μετα-δεδομένα που συλλέγονται είναι: το όνομα, το ψευδώνυμο και ο μοναδικός αριθμός του χρήστη· η ημερομηνία και η τοποθεσία δημιουργίας λογαριασμού· η ημερομηνία και η τοποθεσία δημιουργίας της κάθε ανάρτησης· η ημερομηνία και η τοποθεσία της κάθε σύνδεσης/αποσύνδεσης με την πλατφόρμα· οι πληροφορίες βιογραφικού, όπως ημερομηνία γέννησης, πόλη και χώρα διαμονής, εργασιακό ιστορικό, ενδιαφέροντα, μητρική γλώσσα κ.α· οι “φίλοι” και οι “ακόλουθοι”· η αλληλεπίδραση με αυτούς και η συχνότητα, οι συνήθειες της αλληλεπίδρασης· οι συνήθειες στην περιήγηση μέσα στην πλατφόρμα· ο τύπος της συσκευής και της εφαρμογής που χρησιμοποιείται· ο αριθμός και η συχνότητα των αναρτήσεων, οι φωτογραφίες και τα βίντεο που ανεβάζουν οι χρήστες, τα οποία έχουν τα δικά τους μετα-δεδομένα, αλλά οι εν λόγω πλατφόρμες αξιοποιούν και αναλύουν ακόμα περισσότερα (πχ αναγνώριση προσώπου, συνήθειες και συμπεριφορές στον φυσικό χώρο-χρόνο) και πολλά ακόμα. Μιλώντας για metadata στα social media, δεν περιλαμβάνουμε την καταγραφή κινήσεων στον κυβερνοχώρο γενικά και εκτός της πλατφόρμας ή άλλα που αυτές οι big-tech εταιρείες συλλέγουν από διάφορα σημεία εκτός του κυβερνοχώρου. Μιλάμε μόνο για την δραστηριότητα μέσα στην πλατφόρμα.
Η περιήγηση στο διαδίκτυο περιλαμβάνει τα εξής μετα-δεδομένα, μεταξύ άλλων: σε ποιές ιστο-σελίδες έγινε σύνδεση· πότε και από πού έγινε η επίσκεψη· ο αριθμός και η συχνότητα των επισκέψεων· η δραστηριότητα μέσα στις ιστο-σελίδες, όπως η διάρκεια της επίσκεψης, η διαδρομή του κέρσορα και τα κλίκ· η διεύθυνση IP, ο πάροχος του ίντερνετ, τα χαρακτηριστικά της συσκευής και της οθόνης της, το λειτουργικό σύστημα και ο τύπος του περιηγητή (browser)· τα διάφορα δεδομένα που εισάγει ο χρήστης, όπως τα στοιχεία σύνδεσης στις πλατφόρμες· οι αναζητήσεις στις μηχανές αναζήτησης· τα αποτελέσματα αυτών των αναζητήσεων και σε ποιά από αυτά έγινε σύνδεση· ένας μοναδικός αριθμός/κωδικός που αποδίδει κάθε ιστο-σελίδα στον επισκέπτη (τα γνωστά cookies)· κάποια ακόμα στοιχεία της ιστο-σελίδας που αποθηκεύονται κατά την διάρκεια της επίσκεψης, όπως κάποια εικονίδια και άλλες πληροφορίες σε σχέση με το στήσιμο της ιστο-σελίδας (ο σκοπός της αποθήκευσης αυτών των στοιχείων στον υπολογιστή του χρήστη έχει σκοπό την πιο γρήγορη πρόσβαση στην ίδια σελίδα την δεύτερη φορά).
Αυτά και πολλά ακόμα αποτελούν τις πληροφορίες που “παράγονται” στο ψηφιακό σύμπαν και συλλέγονται στις βάσεις δεδομένων προς επεξεργασία. Φαίνεται ότι κάποιες φορές η διάκριση μεταξύ δεδομένων και μετα-τέτοιων δεν τόσο ξεκάθαρη, για παράδειγμα στις τηλεφωνικές κλήσεις όπου το δεδομένο υποτίθεται ότι είναι η ίδια η συνομιλία, όλα τα στοιχεία που την περιγράφουν και η συλλογή αυτών έχουν μεγαλύτερη σημασία για την εξαγωγή συμπερασμάτων όσον αφορά τις συμπεριφορές, τις σχέσεις και τα σχετικά, από το τί πραγματικά ειπώθηκε στον διάλογο. Ακόμα και οι ειδικοί αναγνωρίζουν ότι η διάκριση είναι κάπως θολή και ουσιαστικά αυτή η θολούρα είναι το αντικείμενο διαπραγμάτευσης μεταξύ των κρατών/εταιρειών που τα θέλουν όλα και τους υπέρμαχους της ιδιωτικότητας· ποιά από αυτά μπορούν να θεωρηθούν “προσωπικά δεδομένα” και ποιά όχι; Ποιά βοηθούν στην ταυτοποίηση του χρήστη και ποιά όχι; H δήλωση του Michael Morell, πρώην αξιωματούχου της cia, είναι χαρακτηριστική: “Δεν υπάρχει ξεκάθαρη διαφορά μεταξύ μετα-δεδομένων και περιεχομένου… ουσιαστικά είναι κάτι σαν συνέχεια (continuum)”.
Αγνοώντας τους τεχνικούς ορισμούς μπορούμε αρχικά να συμπεράνουμε ότι σε κάθε περίπτωση πρόκειται για δεδομένα/data· bytes πληροφοριών που αποθηκεύονται σε σκληρούς δίσκους. Η διάκριση σε μετα-δεδομένα έχει ως βάση την ανθρώπινη ερμηνεία των ειδικών (δηλαδή την παρατήρηση/καταγραφή/ανάλυση/χρονομέτρηση της ανθρώπινης εμπειρίας) για το τί αποτελεί το περιεχόμενο και τί το πλαίσιό του· μια ερμηνεία η οποία, για τις ανάγκες της όλο και μεγαλύτερης καταγραφής, διευρείνεται διαρκώς, και η οποία προορίζεται για επεξεργασία από την μηχανη· αν στη πρώτη φάση, οι κατάλογοι στις βιβλιοθήκες δημιουργούνταν και χρησιμοποιούνταν από ανθρώπους για την ταξινόμηση και εύρεση των βιβλίων, σε αυτή την φάση τώρα και στις επόμενες, τα μετα-δεδομένα είναι άχρηστα χωρίς την μηχανή. Όλον αυτόν τον όγκο δεδομένων δεν είναι δυνατόν να τον επεξεργαστεί ένας άνθρωπος, ούτε ακόμα και μια ομάδα υπερ-ειδικών· Χωρίς την χρήση των “έξυπνων” αλγόριθμων όλα αυτά τα data είναι άχρηστα.

Παλιές και νέες αποθήκες (μετα)δεδομένων. Η χωροταξία παραμένει: ντουλάπες και διάδρομοι.
μια εικόνα χίλια data [4Μετάφραση μερών του άρθρου “What are my photos revealing about me”, από το καθεστωτικό site “The Next Web” (https://tnw.to/4KECt). Το άρθρο έχει αρκετές παραπομπές σε άλλα άρθρα που είναι χρήσιμα για όσα αναφέρει, αλλά δεν θα τις αναπαράγουμε εδώ για οικονομία χώρου.]
Εδώ και χρόνια, οι γνώστες της τεχνολογίας ξέρουν ότι οι φωτογραφίες που τραβήχτηκαν από το τηλέφωνό σας περιέχουν πολλές πληροφορίες που μπορεί να μην θέλετε να αποκαλυφθούν. Το συγκεκριμένο μοντέλο του τηλεφώνου που χρησιμοποιείτε, ο ακριβής χρόνος και η τοποθεσία όπου τραβήχτηκε η φωτογραφία, αποθηκεύονται όλα στα μετα-δεδομένα της φωτογραφίας. Αυτές οι πληροφορίες μπορούν να προβληθούν σχεδόν σε οποιαδήποτε εφαρμογή προβολής εικόνων και μπορούν να χρησιμοποιηθούν για να αποκαλύψουν την συγκεκριμένη ώρα και τόπο – όπου ανάλογα με την εργασία, τις σχέσεις σας ή τη γενική επιθυμία σας για ιδιωτικότητα, ίσως να μην θέλετε να μοιραστείτε με όποιον μπορεί να ψάχνει.
Αλλά τα μετα-δεδομένα δεν είναι το μόνο που πρέπει να σκεφτείτε. Εργαλεία και τεχνικές που κάποτε ήταν διαθέσιμα μόνο στις μυστικές υπηρεσίες για τη συλλογή “ανοιχτών πληροφοριών” (γνωστές και ως Open Source Intelligence ή OSINT, στο εθνικό επίπεδο ασφαλείας) είναι τώρα διαθέσιμα στους ερασιτέχνες. Αυτές οι τεχνικές μπορούν να χρησιμοποιηθούν για την αποκάλυψη προσωπικών στοιχείων αναγνώρισης στις φωτογραφίες σας, ακόμα κι αν έχετε φροντίσει να κλειδώσετε τα μετα-δεδομένα σας.
Ας δούμε μερικά από τα πράγματα που πρέπει να σκεφτείτε πριν μοιραστείτε μια φωτογραφία.
Ποιοί είναι στην φωτογραφία;
Ας ξεκινήσουμε με το κύριο πράγμα για το οποίο πιθανώς χρησιμοποιείτε τη φωτογραφική σας μηχανή: φωτογραφίες της οικογένειας και των φίλων σας. Η τεχνολογία αναγνώρισης προσώπου έχει γίνει τόσο πανταχού παρούσα, που δεν είναι δύσκολο να φανταστεί κανείς ότι κάποιος στη φωτογραφία σας μπορεί να είναι εύκολα αναγνωρίσιμος. Πόσο εύκολο είναι λοιπόν κάποιος να αναγνωρίσει τα άτομα στις φωτογραφίες που δημοσιεύετε στο διαδίκτυο;
Οι αρχές επιβολής του νόμου μπορούν σίγουρα να κάνουν αυτό το είδος ταυτοποίησης. Οι ομοσπονδιακές, πολιτειακές και τοπικές αρχές διαθέτουν βάσεις δεδομένων με φωτογραφίες από κάμερες της αστυνομίας, άδειες οδήγησης, διαβατήρια και φωτογραφίες από συλλήψεις, για χρήση στην πρόληψη και τις έρευνες της εγκληματικότητας (αν και ένα πρόσφατο επταετές πείραμα στο Σαν Ντιέγκο, που χρησιμοποίησε την αναγνώριση προσώπου ως εργαλείο αστυνόμευσης, μόλις τελείωσε με πολύ λίγα στοιχεία ότι πραγματικά βοήθησε στην επίλυση τυχόν εγκλημάτων).
Και η πρόσβαση των αρχών στις φωτογραφίες αυξάνεται. Μια start-up εταιρεία που ονομάζεται clearview AI [5Δες και σχετική αναφορά στο “Αναγνώριση ερήμην | ασταμάτητη μηχανή – 22/1/2020” (https://www.sarajevomag.gr/wp/2020/01/anagnorisi-erimin/)], ισχυρίζεται ότι έχει αποκτήσει περισσότερα από τρία δισεκατομμύρια πρόσωπα και τις αντίστοιχες ταυτότητές τους από δημόσια προφίλ στο youtube, το facebook και άλλες μεγάλες πλατφόρμες. Η εφαρμογή της clearview – η οποία, ισχυρίζονται ορισμένες πηγές των αρχών, είναι πιο ισχυρή από τα υπάρχοντα εργαλεία αναγνώρισης προσώπου που έχουν στην διάθεσή τους μέχρι τώρα - έχει χρησιμοποιηθεί από περισσότερες από 2.200 αρχές επιβολής του νόμου. Ωστόσο, οι ανησυχίες σχετικά με την χρήση αυτού του εργαλείου εκτός των αρχών επιβολής του νόμου έχουν αυξηθεί, με πρόσφατες αποκαλύψεις που δείχνουν ότι η εταιρεία επιτρέπει σε άλλους να δοκιμάσουν την τεχνολογία της, συμπεριλαμβανομένων μεγάλων αλυσίδων λιανικής, σχολείων, καζίνο, ακόμη και ορισμένων μεμονωμένων επενδυτών και πελατών.
Ωστόσο, για τους περισσότερους απλούς χρήστες, η πρόσβαση σε εργαλεία αναγνώρισης προσώπου είναι ακόμη δύσκολη. Εάν δημοσιεύσετε μια φωτογραφία στο facebook, η τεράστια προσαρμοσμένη βάση δεδομένων αναγνώρισης προσώπου που έχει, μπορεί να εντοπίσει άλλους χρήστες του facebook και σε ορισμένες περιπτώσεις θα σας ζητήσει να τους επισημάνετε (tag). Η google και η apple μπορούν επίσης να αναγνωρίσουν πρόσωπα των φίλων και της οικογένειάς σας (που έχετε επισημάνει) στη βιβλιοθήκη φωτογραφιών σας. Αυτές οι ετικέτες είναι ιδιωτικές και τόσο η google όσο και η apple λένε ότι δεν επιχειρούν να ταιριάξουν αυτά τα πρόσωπα με πραγματικές ταυτότητες.
Η ρωσική μηχανή αναζήτησης yandex, η οποία φαίνεται να χρησιμοποιεί μια διαφορετική, πιο ισχυρή τεχνολογία αντιστοίχισης προσώπου, είναι ένας από τους μοναδικούς ιστότοπους που σας επιτρέπει να βρείτε όμοια πρόσωπα που μοιάζουν με αυτά σε μια φωτογραφία που ανεβάσατε.
[…]
Πού τραβήχτηκε η φωτογραφία;
Εάν έχετε δώσει στην εφαρμογή της κάμερας άδεια πρόσβασης στην τοποθεσία σας (gps), τα μετα-δεδομένα των φωτογραφιών σας θα περιέχουν το γεωγραφικό πλάτος και μήκος του σημείου που τραβήχτηκε η φωτογραφία, συμπεριλαμβανομένου του υψομέτρου και συνήθως σε ποια κατεύθυνση ήταν σταρμμένο το τηλέφωνο. Αλλά ακόμα κι αν έχετε κάνει ενέργειες για τον περιορισμό της τοποθεσίας σας, όπως η απενεργοποίηση αυτών των ρυθμίσεων, η τοποθεσία μπορεί να καθοριστεί χρησιμοποιώντας νέα εργαλεία και έξυπνες τεχνικές διερεύνησης. Αυτός είναι ένας τομέας μεγάλου ενδιαφέροντος για την κοινότητα πληροφοριών των ηπα, που αποδεικνύεται από ερευνητικές προσπάθειες όπως το “Πρόγραμμα Εύρεσης” του Intelligence Advanced Research Projects Activity (IARPA’s Finder Program).
Οι ερευνητές δημοσιογράφοι στο Bellingcat χρησιμοποιούν αυτές τις τεχνικές, ξεχωρίζοντας φωτογραφίες των δημόσιων μέσων κοινωνικής δικτύωσης για να βελτιώσουν τον προσδιορισμό των ακριβών τοποθεσιών των εκτοξευτών πυραύλων στην ουκρανία, των τρομοκρατικών εκτελέσεων στη λιβύη και των βομβαρδισμών στη συρία. Αναγνωρίζοντας κτίρια, δέντρα, γέφυρες, πυλώνες ηλεκτροδότησης και κεραίες, οι ερευνητές του Bellingcat βοήθησαν στην ανάπτυξης αυτής της λειτουργίας, της εξονυχιστικής ανάλυσης φωτογραφιών και βίντεο, δημοσιεύοντας τις τεχνικές τους και προσφέροντας εκπαίδευση σε δημοσιογράφους και ερευνητές.
Πινακίδες κυκλοφορίας, ταμπέλες καταστημάτων και οδών, διαφημιστικές πινακίδες, ακόμη και μπλουζάκια στη φωτογραφία σας μπορεί να δώσουν ενδείξεις για τη γλώσσα και μπορούν να βοηθήσουν στον περιορισμό της πιθανής τοποθεσίας. Ασυνήθιστα αρχιτεκτονικά χαρακτηριστικά, όπως εκκλησίες, γέφυρες ή μνημεία, μπορούν να βοηθήσουν στην “αντίστροφη αναζήτηση” της εικόνας. Ακόμη και οι αντανακλάσεις στις φωτογραφίες σας (και στα μάτια σας) μπορούν να περιέχουν πληροφορίες που μπορούν να χρησιμοποιηθούν για γεωγραφική τοποθεσία. Πρόσφατα στην ιαπωνία, μια νεαρή ποπ-σταρ δέχθηκε επίθεση από έναν άνδρα που αναγνώρισε ένα κτίριο στην αντανάκλαση των γυαλιών ηλίου της και αποκάλυψε την τοποθεσία διαμονής της.
Όμως η ανθρώπινη ικανότητα ανίχνευσης έχει τους περιορισμούς της, ενώ οι υπολογιστές γίνονται πολύ καλύτεροι στον εντοπισμό τοποθεσιών αυτόματα. Αν έχετε ανεβάσει εικόνες που δεν έχουν πληροφορίες τοποθεσίας (gps) στην πλατφόρμα φωτογραφιών της google, ίσως έχετε παρατηρήσει ότι ενδέχεται να εξακολουθούν να εμφανίζονται πληροφορίες τοποθεσίας. Η google χρησιμοποιεί αλγόριθμους “ψηφιακής όρασης” (computer vision algorithms) για να προσδιορίσει την πιθανή τοποθεσία για τις λήψεις σας εκτός gps, με βάση το πόσο παρόμοιες είναι οι φωτογραφίες σας με άλλα γνωστά παραδείγματα στα δεδομένα της google, με άλλες εικόνες και με βάση τα σημάδια ημερομηνίας/ώρας στη βιβλιοθήκη σας.
Πότε τραβήχτηκε η φωτογραφία;
Η ώρα και η ημερομηνία είναι δύσκολο να προσδιοριστούν αλλά όχι αδύνατο. Το “πότε” μιας φωτογραφίας μπορεί μερικές φορές να περιοριστεί κοιτάζοντας τον καιρό, τα φυσικά χαρακτηριστικά και το φως.
Οι καιρικές συνθήκες στη φωτογραφία σας μπορούν να δώσουν περισσότερες ενδείξεις για τη λήψη μιας φωτογραφίας από ό,τι νομίζετε. Το wolfram-alpha παρέχει λεπτομερή ιστορικά μετεωρολογικά δεδομένα για οποιονδήποτε μετεωρολογικό σταθμό (σκεφτείτε το σε επίπεδο ταχυδρομικού κώδικα) που συνήθως περιλαμβάνει κάλυψη σύννεφων, θερμοκρασία, βροχόπτωση και άλλα σημαντικά ατμοσφαιρικά δεδομένα που θα μπορούσαν να σας βοηθήσουν να επιβεβαιώσετε την ώρα και την ημερομηνία λήψης μιας φωτογραφίας.
Φυσικά αυτές οι τεχνικές μπορούν επίσης να χρησιμοποιηθούν εξίσου εύκολα για να αποδειχθεί πότε δεν τραβήχτηκε μια φωτογραφία. Δείτε το παράδειγμα της φωτογραφίας ενός πρώην συμβούλου του Τραμπ, του Γιώργου Παπαδόπουλου. Στις αρχές του 2017, ο Παπαδόπουλος άρχισε να συνεργάζεται με ομοσπονδιακούς ανακριτές που ερευνούσαν την ρωσική παρέμβαση στις προεδρικές εκλογές του 2016. Το διαβατήριό του κατασχέθηκε, εμποδίζοντας τον να ταξιδέψει στο εξωτερικό. Αλλά στις 25 Οκτωβρίου 2017 - λίγες μέρες πριν ανακοινώσει την ενοχή του - ο Παπαδόπουλος δημοσίευσε μια φωτογραφία του στο Λονδίνο, με τη λεζάντα #business, που υποδηλώνει ότι βρισκόταν στο ηνωμένο βασίλειο. Δημοσιογράφοι στο Bellingcat συγκρίνοντας κάποια αυτοκόλλητα σε έναν φωτεινό σηματοδότη στο φόντο με εικόνες του google street view, παρατήρησαν ότι αυτά τα σημάδια δεν υπήρχαν πλέον σε πρόσφατες φωτογραφίες. Αποφάσισαν ότι η φωτογραφία είχε τραβηχτεί χρόνια πριν.
(σχόλιο: Με μια έννοια οι πληροφορίες που μπορούν να συγκεντρωθούν από τις παραπάνω πρακτικές επίπτουν στην κατηγορία των μετα-δεδομένων, δηλαδή σε περιφερειακές/περιγραφικές πληροφορίες του περιεχομένου. Απλά ξεφεύγουν από τον “στενό” καθορισμό των μεταδεδομένων μιας φωτογραφίας (όπως τις αναφέραμε πιο πάνω στο κείμενο), και ανοίγονται σε κάθε μικρή λεπτομέρεια που μπορεί να αξιοποιηθεί. Η αναγνώριση προσώπων – που είναι ένα θέμα από μόνο του – βασίζεται ακριβώς σε αυτά που θα ονομάζαμε μετα-δεδομένα· σε αυτές τις λεπτομέρειες, που για την κοινωνικότητα όπως την γνωρίζουμε (;) είναι άχρηστες, αλλά χωρίς αυτές δεν μπορεί να γίνει η μετάφραση του προσώπου στην γλώσσα της μηχανής, όπως οι αποστάσεις των χαρακτηριστικών ενός προσώπου.)
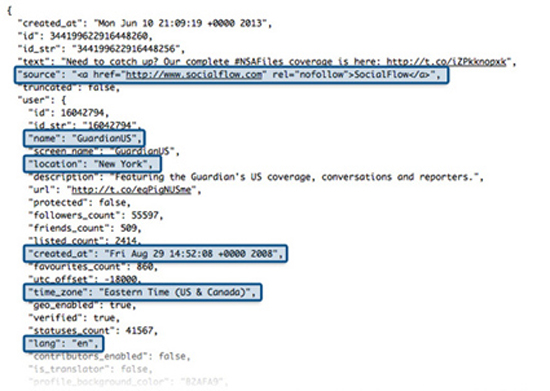
Τα metadata ενός τιτιβίσματος στο twitter.
η πανταχού παρουσία της καταμέτρησης
Οι πλατφόρμες κοινωνικής δικτύωσης (καθώς και άλλες πλατφόρμες, εταιρείες, οργανισμοί κλπ) δεν έχουν πρόσβαση μόνο στις πληροφορίες που συλλέγονται από τις δραστηριότητες μέσα σε αυτές τις πλατφόρμες, αλλά και γενικότερα από τις δραστηριότητες εντός και εκτός του κυβερνο-χώρου. Το παράδειγμα του facebook που ανιχνεύει τις δραστηριότητες όσων δεν έχουν καν λογαριασμό στην πλατφόρμα , είναι ενδεικτικό: [6Μετάφραση μερών του κειμένου: Facebook is tracking me, even though I’m not on facebook (https://www.aclu.org/blog/privacy-technology/internet-privacy/facebook-tracking-me-even-though-im-not-facebook)]
Υπάρχουν τουλάχιστον δύο βασικές κατηγορίες πληροφοριών που διατίθενται στο facebook για όσους δεν έχουν καν λογαριασμό: πληροφορίες από άλλους χρήστες του facebook και πληροφορίες από άλλους ιστότοπους στο ίντερνετ.
Πληροφορίες από άλλους χρήστες
Όταν εγγραφείτε στο facebook, σας ενθαρρύνει να ανεβάσετε τη λίστα των επαφών σας, ώστε ο ιστότοπος να "βρει τους φίλους σας". Το facebook χρησιμοποιεί αυτά τα στοιχεία επικοινωνίας για να μάθει για άτομα, ακόμη και αν αυτά τα άτομα δεν συμφωνούν να συμμετάσχουν. Συνδέει επίσης άτομα με βάση τις κοινές επαφές, ακόμη και αν η κοινή επαφή δεν έχει συμφωνήσει με αυτήν τη χρήση.
Για παράδειγμα, έλαβαin ένα μήνυμα ηλεκτρονικού ταχυδρομείου από το facebook, το οποίο απαριθμεί τα άτομα που με έχουν καλέσει να συμμετάσχω στο facebook: η θεία μου, ένας παλιός συνάδελφος, ένας φίλος από το δημοτικό σχολείο κλπ. Αυτό το μήνυμα ηλεκτρονικού ταχυδρομείου περιλαμβάνει ονόματα και διευθύνσεις ηλεκτρονικού ταχυδρομείου - συμπεριλαμβανομένων του δικό μου ονόματος - και τουλάχιστον ένα web bug [7Μια τεχνική που χρησιμοποιείται σε ιστοσελίδες και emails για να ελέγχεται αν ο χρήστης “άνοιξε” και είδε το περιεχόμενο. Ονομάζεται και web beacon συνήθως.] σχεδιασμένο για να ενημερώνει τους web-servers του facebook όταν ανοίγω το email. Το facebook καταγράφει αυτήν την ομάδα ατόμων ως επαφές μου, παρόλο που δεν έχω συμφωνήσει ποτέ σε αυτό το είδος συλλογής δεδομένων.
Παρομοίως, είμαι βέβαιος ότι είμαι σε μερικές φωτογραφίες που κάποιος έχει ανεβάσει στο facebook - και μάλλον έχω επισημανθεί με ετικέτες (tag) σε μερικές από αυτές. Ποτέ δεν το συμφώνησα, αλλά το facebook μπορεί και το κάνει.
Έτσι, ακόμη και αν αποφασίσετε ότι πρέπει να εγγραφείτε στο facebook, θυμηθείτε ότι ενδέχεται να δίνετε στην εταιρεία πληροφορίες σχετικά με κάποιον άλλο που δεν συμφώνησε να συμμετέχει στην πλατφόρμα παρακολούθησης.
Πληροφορίες από άλλα sites στο internet
Σχεδόν κάθε ιστότοπος που επισκέπτεστε και διαθέτει κάποιο κουμπί “like”, ενημερώνει το facebook για τις συνήθειες περιήγησής σας. Ακόμα κι αν δεν κάνετε κλικ στο κουμπί “like”, το πρόγραμμα περιήγησής (web-browser, όπως o firefox) στείλει αίτημα στους servers του facebook για την εμφάνιση του κουμπιού στην ιστοσελίδα. Αυτό το αίτημα περιλαμβάνει πληροφορίες που αναφέρουν το όνομα της σελίδας που επισκέπτεστε και τυχόν cookies ειδικά για το facebook που μπορεί να έχει συλλέξει το πρόγραμμα περιήγησής σας. (Δείτε την περιγραφή του facebook για αυτή την διαδικασία [8What information does Facebook get when I visit a site with the Like button? - https://www.facebook.com/help/186325668085084]) Αυτό ονομάζεται “αίτημα τρίτου φορέα” (third-party request).
Αυτό επιτρέπει στο facebook να δημιουργήσει μια λεπτομερή εικόνα του ιστορικού περιήγησής σας - ακόμη και αν δεν έχετε επισκεφθεί ποτέ το facebook απευθείας, πόσο μάλλον να έχετε ανοίξει λογαριασμό εκεί.
Σκεφτείτε τις περισσότερες από τις ιστοσελίδες που έχετε επισκεφτεί - πόσες από αυτές δεν έχουν κουμπί “like”; Εάν διαχειρίζεστε έναν ιστότοπο και συμπεριλαμβάνετε ένα κουμπί “like” σε κάθε σελίδα, βοηθάτε το facebook να δημιουργήσει το προφίλ των επισκεπτών σας, ακόμη και εκείνων που απέχουν από την πλατφόρμα. Τα κουμπιά “share” του facebook σε άλλους ιστότοπους - μαζί με άλλα εργαλεία - λειτουργούν λίγο διαφορετικά από το κουμπί “like”, αλλά κάνουν αποτελεσματικά το ίδιο πράγμα.
Τα προφίλ που δημιουργεί το facebook για μη-χρήστες δεν περιλαμβάνουν απαραίτητα τις λεγόμενες "προσωπικές πληροφορίες" (Personally Identifiable Information - PII), όπως ονόματα ή διευθύνσεις ηλεκτρονικού ταχυδρομείου. Αλλά περιλαμβάνουν αρκετά μοναδικά μοτίβα. Χρησιμοποιώντας το NetLog του chromium [9Ένα εργαλείο του chrome με το οποίο μπορεί να δει κάποιος τεχνικές πληροφορίες για το τί συμβαίνει στο background όταν “σερφάρει” στο διαδίκτυο.], έκανα μια απλή δοκιμή περιήγησης πέντε λεπτών την περασμένη εβδομάδα που περιελάμβανε επισκέψεις σε διάφορους ιστότοπους - αλλά όχι στο facebook. Σε αυτό το τεστ, τα δεδομένα χωρίς PII που στάλθηκαν στο facebook περιελάμβαναν πληροφορίες σχετικά με το ποια άρθρα ειδήσεων διάβασα, τις διατροφικές μου προτιμήσεις και τα χόμπι μου.
Δεδομένης της ακρίβειας αυτού του είδους χαρτογράφησης και στόχευσης, οι προσωπικές πληροφορίες μου (PII) δεν είναι απαραίτητες για την ταυτοποίησή μου. Πόσοι vegans εξετάζουν τις προδιαγραφές για ανταλλακτικά υπολογιστή από τα γραφεία της ACLU, διαβάζοντας για την Cambridge Analytica; Εν πάση περιπτώσει, εάν το facebook συνδύαζε αυτές τις πληροφορίες με το “web bug” από το προαναφερθέν μήνυμα ηλεκτρονικού ταχυδρομείου - το οποίο συνδέεται σαφώς με το όνομά μου και τη διεύθυνση ηλεκτρονικού ταχυδρομείου μου - δεν χρειάζεται και πολύ φαντασία.
Θα έμενα έκπληκτος αν το facebook δεν συνέδεε αυτές τις κουκκίδες, με δεδομένους τους στόχους που ισχυρίζεται για τη συλλογή δεδομένων: “Χρησιμοποιούμε τις πληροφορίες που έχουμε για να βελτιώσουμε τα συστήματα διαφήμισης και μέτρησης, ώστε να μπορούμε να προβάλλουμε σχετικές διαφημίσεις εντός και εκτός των υπηρεσιών μας και να μετράμε την αποτελεσματικότητα και την προσέγγιση διαφημίσεων και υπηρεσιών.”
Αυτό είναι, στην ουσία, ακριβώς αυτό που έκανε η Cambridge Analytica.
[…]
Υπάρχει και μια τρίτη κατηγορία πληροφοριών που συλλέγει το facebook, εκτός της πλατφόρμας: όσες μπορούν να εντοπισθούν στον φυσικό χώρο. Μέσω μια υπηρεσίας με το όνομα “offline conversions” μπορεί να μετρηθεί η απήχηση που έχουν στον πραγματικό κόσμο, οι διαφημίσεις στο facebook. Καταγράφοντας τις αγορές στα καταστήματά, τις παραγγελίες μέσω τηλεφώνου, τις κρατήσεις και άλλα, οι επιχειρήσεις μπορούν να φτιάξουν μια λίστα με αυτές τις συναλλαγές και τα στοιχεία των πελατών (όνομα, τηλέφωνο, email κλπ), την οποία θα “ανεβάσουν” στο facebook, ώστε να γίνει αντιστοίχηση με όσους/ες έχει εκείνο στην βάση των χρηστών του. Έτσι μπορούν να ξέρουν, αν για παραδειγμα η αγορά έγινε μετά από μια συγκεκριμένη αναζήτηση ή αν είχαν κλικάρει πάνω στην διαφήμιση. Ίσως τώρα βγάζει κάποιο νόημα το γιατί μας ζητάνε email και τηλέφωνο όταν κάνουμε μια αγορά...

Μια έρευνα του georgetown university έδειξε πως περισσότεροι από τους μισούς ενήλικες αμερικάνους βρίσκονται σε μια βάση δεδομένων προσώπων των αρχών ασφαλείας).
τα παράγωγα
Ο βασικός στόχος της συλλογής και της επεξεργασίας αυτών των τεράστιων όγκων μετα-δεδομένων είναι η ανάλυση και η διαμόρφωση των συμπεριφορών [10Δες και το “big data: επιτήρηση και διαμόρφωση συμπεριφορών στην 4η βιομηχανική επανάσταση” - Cyborg #16 10/2019] είτε για εμπορικούς σκοπούς, είτε για την γενικότερη επιτήρηση (δύο, όχι και πολύ διακριτά πεδία). Η καταγραφή όλων των δια-μεσολαβημένων από το δια-δίκτυο πράξεών μας, και των περιφερειακών πληροφοριών αυτών των πράξεων – δηλαδή η καταγραφή του περιεχομένου και της περιγραφής του, όπου όσο αυξάνεται η δυνατότητα διείσδυσης του αλγορίθμου, αυξάνεται και το επίπεδο της λεπτομέρειας σε αυτήν – διαμορφώνει αυτό που ονομάζεται ψηφιακό προφίλ. Μια ψηφιακή ταυτότητα τεσσάρων διαστάσεων, καθώς οι συμπεριφορές αποτιμούνται μέσα στον (κυβερνο)χώρο και τον (κυβερνο)χρόνο.
Σχηματικά, μπορούμε να περιγράψουμε την ψηφιακή ταυτότητα ως τριών επιπέδων. Στο πρώτο ανήκουν άμεσα οι διαμεσολαβημένες (άμεσα ή έμμεσα) από το δια-δίκτυο δραστηριότητες, όπως η περιήγηση και η αναζητήσεις στο ίντερνετ, τα κείμενα και οι φωτογραφίες που “ανεβάζουμε”, οι εφαρμογές που χρησιμοποιούμε, οι ηλεκτρονικές πληρωμές κλπ. Το δεύτερο περιλαμβάνει τις συμπεριφορικές παρατηρήσεις· οι πληροφορίες/metadata που περιγράφουν τις άμεσες δραστηριότητες, με τρόπο που μας διαφεύγουν από την άμεση παρατήρηση/πράξη. Ο χρόνος που ξοδεύουμε online, οι κατηγορίες των περιεχομένων που επισκεπτόμαστε, ο τρόπος και η ταχύτητα που χρησιμοποιούμε τα κουμπιά/πλήκτρα, οι κινήσεις στις οθόνες επαφής κλπ· και οι συσχετισμοί μεταξύ τους. Και στο τρίτο επίπεδο είναι η ερμηνεία της μηχανής. Η αναλυση των δεδομένων από “έξυπνους” αλγόριθμους, και η εξαγωγή στατιστικών συμπερασμάτων, όχι μόνο για το τί κάνουμε, αλλά για το ποιοί είμαστε· η (μηχανική) ανάλυση της συμπεριφοράς.
Μεταφράζουμε από μια έρευνα της “επιτροπής απορρήτου του καναδά” (επίσημο όργανο της καναδικής κυβέρνησης, που ιδρύθηκε το 1977): [11Metadata and Privacy: A technical and Legal Overview - October 2014 (https://www.priv.gc.ca/en/opc-actions-and-decisions/research/explore-privacy-research/2014/md_201410/#fn6-rf)]
Πράγματι, τα μετα-δεδομένα μπορεί μερικές φορές να είναι πιο αποκαλυπτικά από το ίδιο το περιεχόμενο. Στην ψηφιακή εποχή, σχεδόν κάθε διαδικτυακή δραστηριότητα αφήνει κάποιο είδος προσωπικού ίχνους. Ο επιστήμονας υπολογιστών Daniel Weitzner θεωρεί τα μετα-δεδομένα “αναμφισβήτητα πιο αποκαλυπτικά [από το περιεχόμενο], επειδή στην πραγματικότητα είναι πολύ πιο εύκολο να αναλύσουμε τα μοτίβα σε ένα μεγάλο σύμπαν μετα-δεδομένων και να τα συσχετίστουμε με γεγονότα στον πραγματικό κόσμο, από το να κάνουμε μια σημασιολογική (semantic) ανάλυση όλων των e-mail κάποιου και όλων των τηλεφωνικών κλήσεων.” Ακόμα και οι όροι που εισάγονται στις μηχανές αναζήτησης μπορούν να χρησιμοποιηθούν για την αναγνώριση ατόμων και για την αποκάλυψη ευαίσθητων πληροφοριών σχετικά με αυτά. Ο John Battelle επινόησε τον όρο “βάση δεδομένων των προθέσεων” (database of intentions) που περιγράφει ως “τα συνολικά αποτελέσματα κάθε αναζήτησης που έχει εισαχθεί ποτέ, κάθε λίστας αποτελεσμάτων που έχει υποβληθεί ποτέ, και κάθε διαδρομής που έχει ληφθεί ως αποτέλεσμα”. Ο Battelle δηλώνει ότι “Οι πληροφορίες αντιπροσωπεύουν, σε μια συνολική μορφή, ένα υποκατάστατο/δείκτη (placeholder) για τις προθέσεις της ανθρωπότητας - μια τεράστια βάση δεδομένων επιθυμιών, αναγκών και συμπαθειών που μπορούν να ανακαλυφθούν, να κληθούν, να αρχειοθετηθούν, να παρακολουθούνται και να αξιοποιούνται με κάθε είδους τρόπο. Ποτέ στην ιστορία του πολιτισμού δεν υπήρξε ένα τέτοιο τέρας, αλλά είναι σχεδόν εγγυημένο ότι θα αναπτυχθεί εκθετικά από εδώ και πέρα”.
Και από μια αναφορά της αμερικανικής ένωσης πολιτικών ελευθεριών της Καλιφόρνια (ACLU of California): [12Metadata: Piecing together a privacy solution – February 2014 (https://www.aclunc.org/publications/metadata-piecing-together-privacy-solution)]
Στην πραγματικότητα, η εξόρυξη μετα-δεδομένων δεν μπορεί μόνο να εκθέσει ευαίσθητες πληροφορίες για το παρελθόν, αλλά και να επιτρέψει σε έναν παρατηρητή να προβλέψει μελλοντικές ενέργειες. Για παράδειγμα, έρευνες έχουν δείξει ότι η μελλοντική τοποθεσία και οι δραστηριότητες ενός ατόμου μπορούν να προβλεφθούν αναζητώντας μοτίβα στους φίλους του και το ιστορικό τοποθεσίας συνεργατών. Ένας εμπειρογνώμονας ασφαλείας προειδοποίησε επίσης ότι ο εντοπισμός τηλεφωνικών κλήσεων από βασικά στελέχη μιας εταιρείας προς ή από έναν ανταγωνιστή, έναν πληρεξούσιο ή μια χρηματιστηριακή εταιρεία μπορεί να αποκαλύψει τις πιθανότητες μιας εταιρικής εξαγοράς πριν γίνει οποιαδήποτε δημόσια ανακοίνωση.
Με μια δεύτερη ματιά, η αντίληψη που μπορεί να έχουμε για τα (big) data ως ένας μεγάλος όγκος πληροφοριών, διευρείνεται για να συμπεριλάβει και τον παράγοντα του χρόνου. Οι “βάσεις δεδομένων των προθέσεων” δεν είναι στατικές· τραβάνε γραμμές και εντοπίζουν αλλη-επιδράσεις μέσα στον χρόνο. Από αυτή την διαδικασία – και με αυτή την λογική, την λογική του αλγόριθμου - αναλύουν και αντιλαμβάνονται το παρελθόν, προσπαθώντας να μαντέψουν ή/και να διαμορφώσουν το μέλλον. Θα μπορούσαμε να ισχυριστούμε ότι η μεσολάβηση της μηχανής, αλλάζει την ίδια την γλώσσα που ερμηνεύουμε το παρελθόν, το παρόν και φανταζόμαστε το μέλλον; Ερώτηση που σίγουρα δεν χωράει στο παρόν κείμενο, αλλά προκύπτει αυθόρμητα, όταν σκάει μπροστά μας η μηχανή πρόβλεψης των προθέσεων.
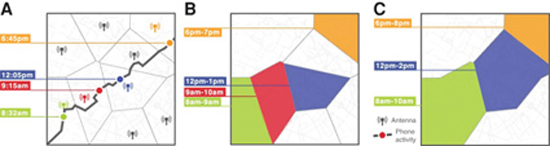
Αναπαράσταση του συνδυασμού ανώνυμων σημείων/δεδομένων από την χρήση κινητού τηλεφώνου, σε στόχο την ταυτοποίηση, από μια άλλη έρευνα δημοσιευμένη στο nature.com το 2013, με τίτλο “unique in the crowd”.
η ταυτοποίηση του ανώνυμου
Ως “παράπλευρη απώλεια” αυτής της συλλογής μετα-δεδομένων και της δημιουργίας της ψηφιακής ταυτότητας προκύπτει ο εφιάλτης των υπέρμαχων της ιδιωτικότητας: η ταυτοποίηση του ανώνυμου. Μια έρευνα του mit το 2018 έδειξε πώς μπορεί να γίνει ταυτοποιήση κάποιου ατόμου, με την χρήση μεγάλων συνόλων ανώνυμων μετα-δεδομένων. Μεταφράζουμε από την σχετική δημοσίευση: [13The privacy risks of compiling mobility data]
Μια νέα μελέτη από ερευνητές του MIT διαπιστώνει ότι η αυξανόμενη πρακτική της συλλογής μαζικών, ανώνυμων συνόλων δεδομένων σχετικά με τα μοτίβα κίνησης των ανθρώπων είναι ένα δίκοπο μαχαίρι: παρόλο που μπορεί να δώσει βαθιές γνώσεις για την έρευνα της ανθρώπινης συμπεριφοράς, θα μπορούσε επίσης να θέσει σε κίνδυνο τα ιδιωτικά δεδομένα των ανθρώπων.
Εταιρείες, ερευνητές και άλλες οντότητες έχουν αρχίσει να συλλέγουν, να αποθηκεύουν και να επεξεργάζονται ανώνυμα δεδομένα που περιέχουν "στίγματα τοποθεσίας" (γεωγραφικές συντεταγμένες και χρονικά σήματα) των χρηστών. Τα δεδομένα μπορούν να ληφθούν από αρχεία κινητών τηλεφώνων, συναλλαγές με πιστωτικές κάρτες, έξυπνες κάρτες δημόσιων συγκοινωνιών, λογαριασμούς twitter και εφαρμογές κινητών. Η συγχώνευση αυτών των συνόλων δεδομένων θα μπορούσε να παρέχει πλούσιες πληροφορίες για το πώς ταξιδεύουν οι άνθρωποι, για παράδειγμα, για τη βελτιστοποίηση των μεταφορών και του πολεοδομικού σχεδιασμού, μεταξύ άλλων.
Αλλά με τα big data προκύπτουν μεγάλα ζητήματα απορρήτου: Τα στίγματα τοποθεσίας είναι εξαιρετικά προσανατολισμένα σε άτομα και μπορούν να χρησιμοποιηθούν για κακόβουλους σκοπούς. Πρόσφατη έρευνα έδειξε ότι, λαμβάνοντας υπόψη μόνο μερικά τυχαία επιλεγμένα σημεία σε σύνολα δεδομένων κινητικότητας, κάποιος θα μπορούσε να αναγνωρίσει και να μάθει ευαίσθητες πληροφορίες για τα άτομα. Με τα συγχωνευμένα σύνολα δεδομένων κινητικότητας, αυτό γίνεται ακόμη πιο εύκολο: Κάποιος θα μπορούσε ενδεχομένως να αντιστοιχίσει ένα σύνολο ανώνυμων δεδομένων με τις διαδρομές των χρηστών, με ταυτοποιημένα δεδομένα από ένα άλλο, για να ταυτοποιήσει τα ανώνυμα δεδομένα.
Στην μελέτη τους, οι ερευνητές συνδύασαν δύο σύνολα ανώνυμων δεδομένων «χαμηλής πυκνότητας» - λίγες εγγραφές την ημέρα - σχετικά με τη χρήση κινητών τηλεφώνων και τις προσωπικές μετακινήσεις με μμμ στη Σιγκαπούρη, που καταγράφηκαν για πάνω από μία εβδομάδα το 2011. Τα δεδομένα κινητής τηλεφωνίας προήλθαν από έναν μεγάλο φορέα δικτύου κινητής και περιελάμβαναν χρονικές σημάνσεις και γεωγραφικές συντεταγμένες σε περισσότερες από 485 εκ. εγγραφές για περισσότερους από 2 εκ. χρήστες. Τα δεδομένα μετακίνησης περιείχαν πάνω από 70 εκ. αρχεία με χρονικά στίγματα για άτομα που μετακινούνται στην πόλη.
Το μοντέλο των ερευνητών επιλέγει έναν χρήστη από το ένα σύνολο δεδομένων και βρίσκει έναν χρήστη από το άλλο σύνολο δεδομένων με μεγάλο αριθμό αντίστοιχων στιγμάτων θέσης. Με απλά λόγια, καθώς ο αριθμός των σημείων αντιστοίχισης αυξάνεται, μειώνεται η πιθανότητα λανθασμένης αντιστοίχησης. Αφού ταιριάξει έναν ορισμένο αριθμό σημείων σε μια διαδρομή, το μοντέλο αποκλείει τη δυνατότητα ψευδής αντιστοίχησης.
Εστιάζοντας στους τυπικούς χρήστες, υπολόγισαν ποσοστό επιτυχημένης αντιστοιχίας 17% σε μια εβδομάδα συγκεντρωμένων δεδομένων και περίπου 55% για τέσσερις εβδομάδες. Αυτή η εκτίμηση ανεβαίνει στο 95% περίπου με τα δεδομένα να συλλέγονται σε διάστημα 11 εβδομάδων.
Τι σημαίνει αυτό; Σημαίνει ότι η ταυτοποίηση μπορεί να γίνει με τον συνδυασμό των μετα-δεδομένων, τα οποία μπορεί να είναι (και) ανώνυμα! Εδώ ο “αγώνας για ιδιωτικότητα” θολώνει τα νερά. Από την μια υπάρχει η “καλών προθέσεων” ανάλυση των συμπεριφορών για να βελτιώσουμε τις πόλεις και τα λοιπά, και από την άλλη το πρόβλημα της έκθεσης των προσωπικών δεδομένων. Σε σχετικά νομικά κείμενα που βρήκαμε, ο ορισμός του προσωπικού δεδομένου αφορούσε τις πληροφορίες που συνδέονται άμεσα με ένα ταυτοποιημένο άτομο. Έτσι, σύμφωνα με αυτόν τον ορισμό, τα μετα-δεδομένα δεν επίπτουν στα προσωπικά δεδομένα, και ξεκινάει ο μεγάλος διάλογος για τον επαναπροσδιορισμό του ορισμού και την οριοθέτηση της συλλογής και της ταυτοποίησης των δεδομένων από τις εταιρείες και τα κράτη. Δεν θα μπούμε σε αυτά τα βαθειά νερά τώρα.
σύντομος επίλογος

Κρατώντας μια απόσταση, τα ζητήματα που προκύπτουν από την συλλογή/επεξεργασία (μετα)δεδομένων είναι δύο: πρώτον η καταγραφή/ανάλυση των συμπεριφορών από κράτη/εταιρείες, με σκοπό την διαμόρφωσή τους, και δεύτερον, η αναγνώριση/αυτοποίηση από το κράτος/υπηρεσίες, με σκοπό την επιτήρηση/καταστολή και την επιβολή του νόμου.
Το θέμα της ιδιωτικότητας/ανωνυμίας, αν και (ίσως) χρήσιμο μέχρι ένα σημείο ως “κυβερνο-οδόφραγμα”, είναι παραπλανητικό στην προσέγγιση μιας συνολικής πολιτικής απάντησης. Ο αγώνας για ιδιωτικότητα δεν θέλει να είμαστε ανώνυμοι όταν πληρώνουμε τον λογαριασμό του νερού, τα ασφάλιστρα ή τα πρόστιμα. Εκεί δέχεται ότι πρέπει να υπάρχει η ταυτοποίηση· πώς θα γινόταν και αλλιώς; (Βέβαια ακόμα και έτσι, πάλι παραπλανητικός θα ήταν). Ο αγώνας για την ιδιωτικότητα έχει να κάνει (και) με την συλλογή μετα-δεδομένων στον σωρό, στην οποία θα πρέπει να υπάρχει ανωνυμία· αλλά απ’ ότι φαίνεται, γίνεται κι έτσι η δουλειά – no problem!
Αν η εξουσία χρειάζεται την ταυτοποίηση ώστε να επιβάλει τον νόμο – φαίνεται ότι πλεόν έχει στην διάθεσή της και νέους “έμμεσους” τρόπους ταυτοποίησης - η επιστήμη της ανάλυσης συμπεριφορών, δεν ενδιαφέρεται για το πώς μας λένε, αλλά για το ποιοί είμαστε. Η μηχανή που χρησιμοποιεί χιλιάδες εθελοντές για το εμβόλιο, αδιάφορη για τα ονόματά τους, εστιάζει στην ατομική τους αντίδραση, για να παράξει κανονικότητες που θα τις επιβάλλει σε ταυτότητες. Εκεί, το “δικαίωμα στην ιδιωτικότητα” είναι απλά περιττό.
Wintermute
Σημειώσεις
1 - Τί είναι τα data και σε ποιόν ανήκουν; - Cyborg #13, Οκτώβρης 2018
[ επιστροφή]
2 - Ένα κομμάτι κώδικα που υπάρχει σε κάθε email και έχει μια σύνοψη τέτοιων μετα-πληροφοριών.
[ επιστροφή]
3 - Έναν (μάλλον) εξαντλητικό κατάλογο των metadata που μπορεί να έχει μια φωτογραφία μπορείτε να δείτε εδώ>>
[ επιστροφή]
4 - Μετάφραση μερών του άρθρου “What are my photos revealing about me”, από το καθεστωτικό site “The Next Web”. Το άρθρο έχει αρκετές παραπομπές σε άλλα άρθρα που είναι χρήσιμα για όσα αναφέρει, αλλά δεν θα τις αναπαράγουμε εδώ για οικονομία χώρου.
[ επιστροφή]
5 - Δες και σχετική αναφορά στο “Αναγνώριση ερήμην | ασταμάτητη μηχανή – 22/1/2020”
[ επιστροφή]
6 - Μετάφραση μερών του κειμένου: Facebook is tracking me, even though I’m not on facebook
[ επιστροφή]
7 - Μια τεχνική που χρησιμοποιείται σε ιστοσελίδες και emails για να ελέγχεται αν ο χρήστης “άνοιξε” και είδε το περιεχόμενο. Ονομάζεται και web beacon συνήθως.
[ επιστροφή]
8 - What information does Facebook get when I visit a site with the Like button?
[ επιστροφή]
9 - Ένα εργαλείο του chrome με το οποίο μπορεί να δει κάποιος τεχνικές πληροφορίες για το τί συμβαίνει στο background όταν “σερφάρει” στο διαδίκτυο.
[ επιστροφή]
10 - Δες και το “big data: επιτήρηση και διαμόρφωση συμπεριφορών στην 4η βιομηχανική επανάσταση” - Cyborg #16 10/2019
[ επιστροφή]
11 - Metadata and Privacy: A technical and Legal Overview - October 2014
[ επιστροφή]
12 - Metadata: Piecing together a privacy solution – February 2014
[ επιστροφή]
13 - The privacy risks of compiling mobility data
[ επιστροφή]